go 并发模型整理(一)
go 语言的并发是整个语言的精髓所在,在语言层面灵活的处理协程,可以有效提高程序性能。但是go并发虽然简单,处理不当依然会造成很大的问题,比如内存溢出,比如死锁等等头疼的问题,写模型整理这个模块主要就是想要把一些好的并发模式收集起来积累经验,同时也对容易出问题的地方深入了解。
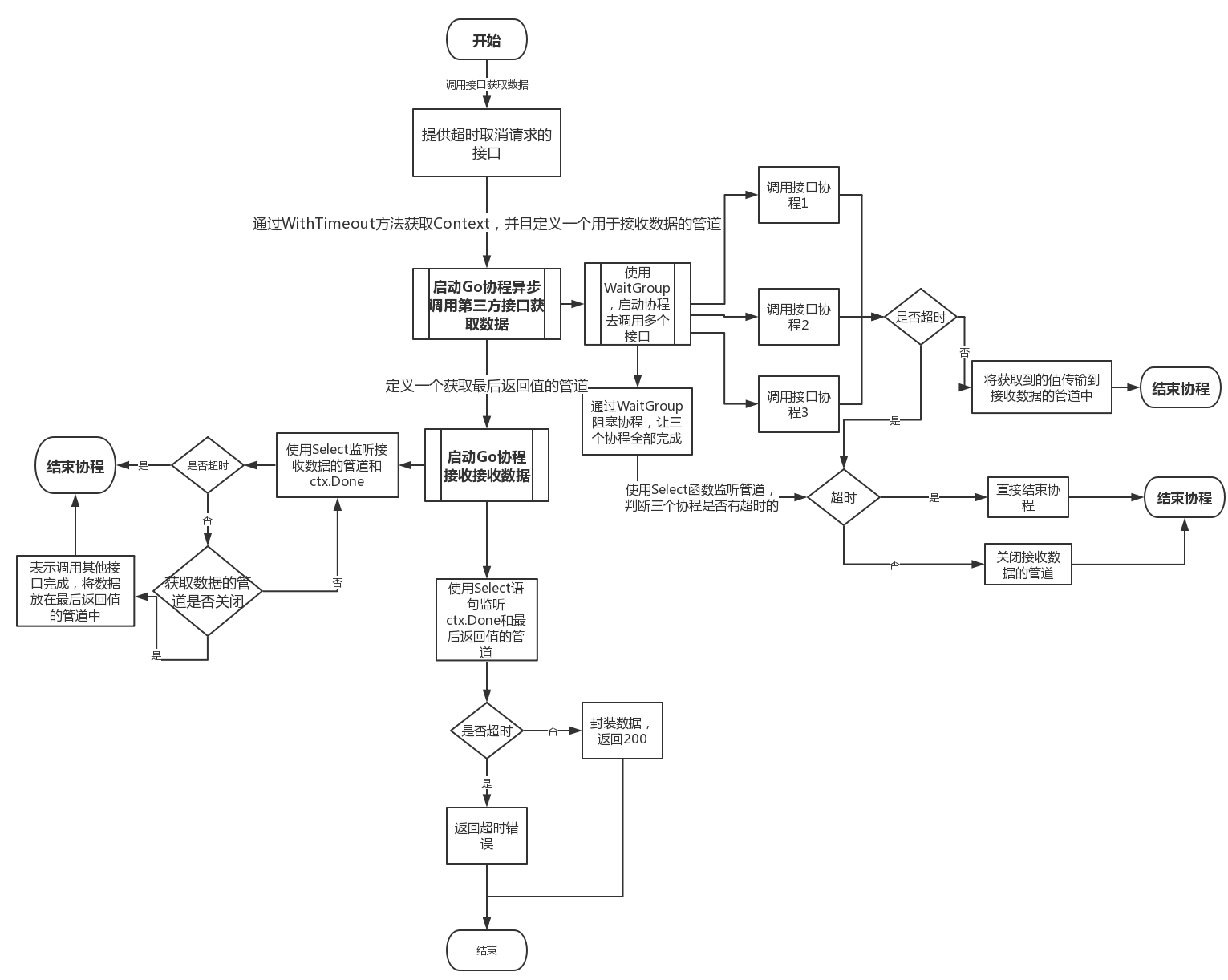
超时取消模型 网上看到的很好的流程图 这是我在看别人博客时看到的一张流程图,但是他的内容并没有完整的代码实现,我感觉这个流程做的很棒,所以自己用代码去实现了一下,希望可以抛砖引玉。代码点击这里看
这个流程图之所以我觉好,是因为 :
考虑的十分细节,每个过程产生的并发的生命周期控制都有涉及,可以做到即使出现问题也可以通过超时的设置优雅退出所有并发。
流程图并不是简单的去实现一个超时退出,而是设计了一些比较通用的业务逻辑。请看下图:
代码实现 先把整个流程拆分一下:发送者 —> 接收者(并发接收) —> 最终结果处理者
其中发送者再次拆分:工人1;工人2;工人3 —> 数据整合者 —> 整合后的最终可以发送的数据
整个流程涉及10个协程,其中三个工人的并发,三个接收者的并发,工人和接收者的并发协程生命周期由其各自的并发池控制,其余全局协程的生命周期总体控制。
超时模型的核心是在超时后保证所有的启动的协程完全退出,最后退出主进程。
不多说了看代码:
发送者:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func dealSendMessage (ress []interface {}) interface var s string for _, v := range ress { s += fmt.Sprintf("last handle results :%v " , v) } return s } func SenderRun (ctx *worker.Context, rwp *worker.WorkPool, awg *sync.WaitGroup, cascade bool ) defer awg.Done() wp := worker.StartWorkPool(ctx, maxCurrencyCount) wp.Dispatch(&worker.Worker1{}) wp.Dispatch(&worker.Worker2{}) wp.Dispatch(&worker.Worker3{}) wp.Stop() select { case <-ctx.TimeoutCtx.Done(): fmt.Println("send ctx timeout " , ctx.TimeoutCtx.Err()) rwp.Stop() return default : if len (worker.DealResultSet) > 0 { rwp.Dispatch(worker.NewReceiver(dealSendMessage(worker.DealResultSet))) } rwp.Stop() return } }
发送者主要是需要启动三个工人协程,去做不同的事情,全部完成后汇总结果进行处理,最终把结果发给接收者。
在发送者的设计中涉及一个worker 接口:
1 2 3 4 type Worker interface { Do(ctx *Context) }
这个接口的作用在于,统一控制不同的工作核心逻辑的触发。三个工作者都实现Worker接口,最终在并发池统一出发和管理。
先看一个worker1 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 type Worker1 struct { BaseWorker } func (w1 *Worker1) Do (ctx *Context) err := w1.Core(ctx) if err != nil { fmt.Println("worker1 has an err: " , err) return } fmt.Println("worker1 has been done " ) } func (w1 *Worker1) Core (ctx *Context) error time.Sleep(1 * time.Second) select { case <-ctx.TimeoutCtx.Done(): return ctx.TimeoutCtx.Err() case DealChan <- "worker1" : return nil } }
这里因为要汇总所有工人的数据处理结果,并最终形成一个新的数据发给接收者,所以设计了一个发送结果处理者:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 var ( DealChan chan interface {} DealResultSet []interface {} ) func init () DealChan = make (chan interface {}) } func dealCore (res interface {}) fmt.Println("deal the result : " , res) DealResultSet = append (DealResultSet, res) } func DealResult (ctx *Context, wg *sync.WaitGroup) defer wg.Done() for { select { case res := <-DealChan: dealCore(res) case <-ctx.TimeoutCtx.Done(): fmt.Println("deal result ctx is timeout" , ctx.TimeoutCtx.Err()) return default : time.Sleep(100 * time.Millisecond) } } }
处理者的管道是全局的,同样处理者也是全局的并不属于发送者管控,当然为了更加通用,可以在发送者内部去管控结果处理者,但考虑到这个设计已经有点过于复杂,违背了超时模型的设计初衷,简单的做了一个全局的处理,全局处理的协程都将归于主进程来管理。也将进行超时管控。
在看一下统一控制触发和管理工人并发的并发池的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 type WorkPool struct { WorkCh chan Worker Wg sync.WaitGroup } func StartWorkPool (ctx *Context, currencyCount int ) *WorkPool wp := WorkPool{ WorkCh: make (chan Worker), } wp.Wg.Add(currencyCount) for i := 0 ; i < currencyCount; i++ { go func (index int ) defer wp.Wg.Done() for w := range wp.WorkCh { w.Do(ctx) } fmt.Printf("workPool number%d stopped \n" , index) }(i) } return &wp } func (wp *WorkPool) Dispatch (w Worker) wp.WorkCh <- w } func (wp *WorkPool) Stop () close (wp.WorkCh) wp.Wg.Wait() }
结合发送者的代码来整体的看发送者的逻辑,就是启动并发池,新建三个不同的 Worker 并发送到并发池,并发池等待所有worker执行完成任务发给发送数据处理者形成发送最终结果发送给接收者。
好啊,发送者比接收者复杂的多,接下来的接收者就简单了。
接收者:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 var LastHandleChan chan interface {}func init () LastHandleChan = make (chan interface {}) } type Receiver struct { BaseWorker Result interface {} } func NewReceiver (result interface {}) *Receiver return &Receiver{ Result: result, } } func (r *Receiver) Do (ctx *Context) err := r.Core(ctx) if err != nil { fmt.Println("receiver has an err: " , err) return } fmt.Println("receiver has been done " ) } func (r *Receiver) Core (ctx *Context) error time.Sleep(1 * time.Second) select { case <-ctx.TimeoutCtx.Done(): return ctx.TimeoutCtx.Err() case LastHandleChan <- r.Result: return nil } } func LastHandle (ctx *Context, awg *sync.WaitGroup) defer awg.Done() for { select { case <-ctx.TimeoutCtx.Done(): fmt.Println("last handle ctx timeout " , ctx.TimeoutCtx.Err()) return case res := <-LastHandleChan: fmt.Printf("the work : %s has been done ! \n" , res) default : time.Sleep(100 * time.Millisecond) } } }
同样的接收者也是一个实现worker接口的类,这个类在把接收结果直接放入,核心逻辑就是把类中的发送结果发送到最终处理者那里,最终处理者依然处理成全局的 核心逻辑就是上面代码的LastHandle().
服务启动:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func ServerRun (ctx *worker.Context, awg *sync.WaitGroup) awg.Add(3 ) go worker.LastHandle(ctx, awg) receiverWp := worker.StartWorkPool(ctx, maxCurrencyCount) go worker.DealResult(ctx, awg) go SenderRun(ctx, receiverWp, awg, false ) }
启动服务其实就是启动接收者,发送者,发送结果处理者,最终结果处理者。其中接收者其实也是启动了一个并发池,并把并发池实体传入发送者,发送者在处理完成数据后,把数据发送给接收者并发池。
main:
1 2 3 4 5 6 7 8 9 10 11 12 func main () ctx := worker.GetContext(10 * time.Second) awg := sync.WaitGroup{} ServerRun(ctx, &awg) awg.Wait() fmt.Println("successful" ) }
main函数其实就是做出全局上下文和全局协程控制的wait group 并将服务启动并等待所有协程结束退出主进程,,我们启动 main 函数。
可以看到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 deal the result : worker3 worker3 has been done worker2 has been done workPool number1 stopped deal the result : worker2 workPool number0 stopped deal the result : worker1 worker1 has been done workPool number2 stopped workPool number0 stopped workPool number2 stopped receiver has been done workPool number1 stopped the work : last handle results :worker3 last handle results :worker2 last handle results :worker1 has been done ! deal result ctx is timeout context deadline exceeded last handle ctx timeout context deadline exceeded successful
在所有的发送任务完成后,接收者接收到任务并发送给最终处理者,最终处理者打出了last handle results :worker3 last handle results :worker2 last handle results :worker1 has been done ! 三个工作进行合并的处理的结果,最后等待全局的发送结果处理者,和最终结果处理者超时退出主进程退出。符合预期。
我们把超时时间缩短到极短100毫米试一试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 deal result ctx is timeout context deadline exceeded last handle ctx timeout context deadline exceeded worker3 has an err: context deadline exceeded worker1 has an err: context deadline exceeded workPool number2 stopped workPool number1 stopped worker2 has an err: context deadline exceeded workPool number0 stopped send ctx timeout context deadline exceeded workPool number1 stopped workPool number0 stopped workPool number2 stopped successful
发现所有启动的协程都超时退出了包括两个并发池的起的6个协程都立刻依次退出后主进程退出,同样符合预期。
代码在这里:代码