算法专栏 (三):数组 在每一种编程语言中,基本都会有数组这种数据类型。不过,它不仅仅是一种编程语言中的数据类型,还是一种最基础的数据结构。尽管数组看起来非常基础、简单,但是我估计很多人都并没有理解这个基础数据结构的精髓。
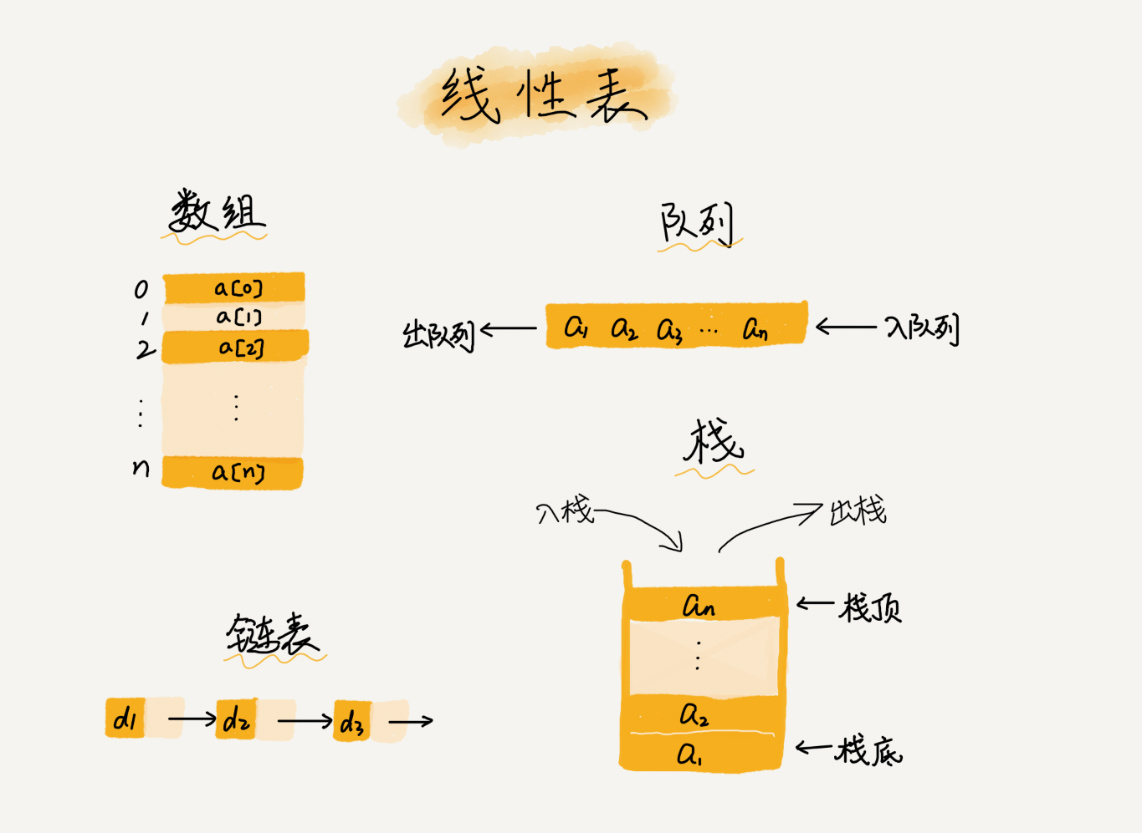
定义及如何实现随机访问? 数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
这个定义里有几个关键词:
第一是线性表 (Linear List)。顾名思义,线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构。
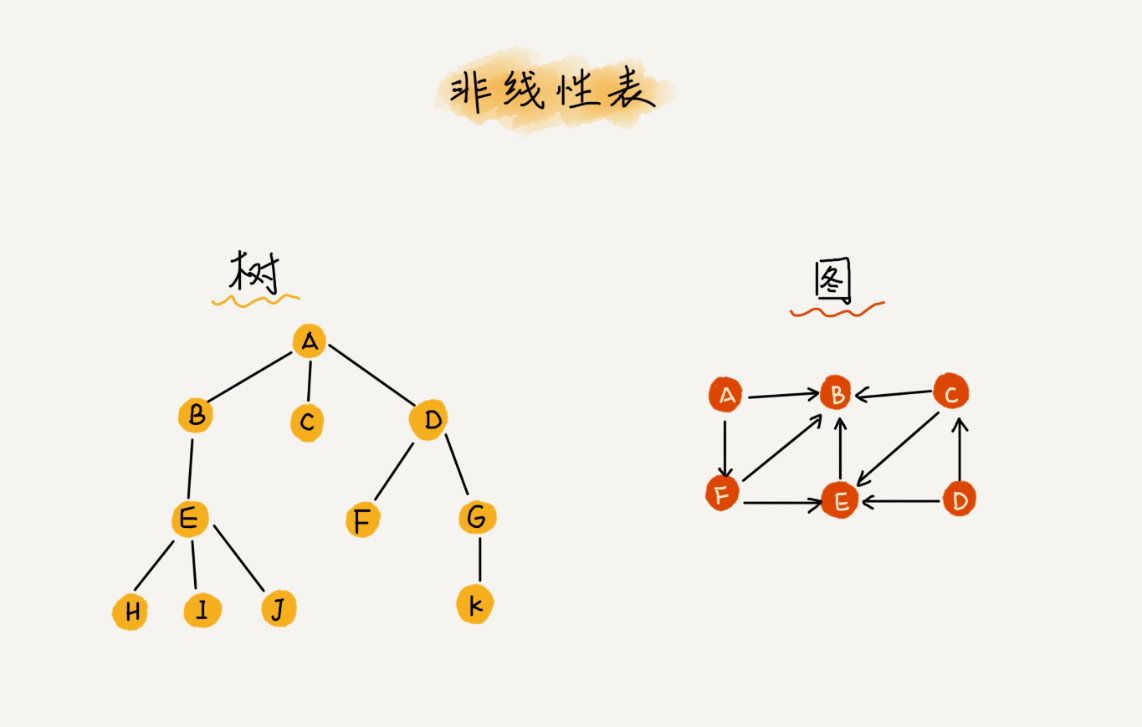
而与它相对立的概念是非线性表 ,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
第二个是连续的内存空间和相同类型的数据 。正是因为这两个限制,它才有了一个堪称“杀手锏”的特性:“随机访问”。但有利就有弊,这两个限制也让数组的很多操作变得非常低效,比如要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据搬移工作。
说到数据的访问,那你知道数组是如何实现根据下标随机访问数组元素的吗?
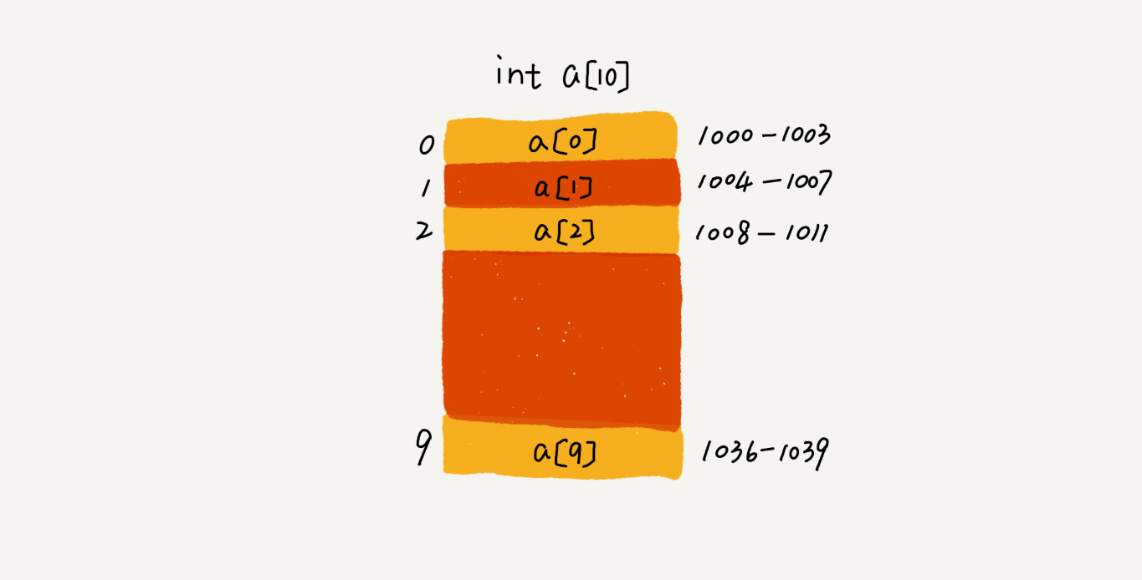
我们拿一个长度为 10 的 int 类型的数组 int[] a = new int[10] 来举例。在我画的这个图中,计算机给数组 a[10],分配了一块连续内存空间 1000~1039,其中,内存块的首地址为 base_address = 1000。
我们知道,计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:
1 a[i]_address = base_address + i * data_type_size
为了好理解,我们看一下go语言中切片的结构数据
首先我们打印出数组的地址,然后再依次打印出数组中每个数据的地址,代码如下:
1 2 3 4 5 6 7 func TestGetCapOfSlice (t *testing.T) array := [7 ]int {1 , 2 , 3 , 4 , 5 , 6 , 7 } t.Logf("the address of array %p" , &array) for i := 0 ; i < len (array); i++ { t.Logf("%p" , &array[i]) } }
打印结果:
1 2 3 4 5 6 7 8 9 10 11 === RUN TestGetCapOfSlice kline_test.go:126: the address of array 0xc00002e180 kline_test.go:128: 0xc00002e180 kline_test.go:128: 0xc00002e188 kline_test.go:128: 0xc00002e190 kline_test.go:128: 0xc00002e198 kline_test.go:128: 0xc00002e1a0 kline_test.go:128: 0xc00002e1a8 kline_test.go:128: 0xc00002e1b0 --- PASS: TestGetCapOfSlice (0.00s) PASS
可以看到其中数组的地址 (16进制) 是首个数据的地址,数组中每个数据的地址跟据数组中的次序依次加8的,也很好理解即每个int类型的数据都占8个字节的内存,(题外话 int 类型是根据cpu的位数来决定的,cpu 为64位那么每个位置就分配8字节也就是64位,也就是-2^32~2^32这个区间范围不可超出,同理可得32位的c pu 对应的就是4字节32位),如果你把类型换成byte那么一个位置只有1字节,如果换成 string 那么一个位置就是16个字节。
综上,数组仅仅记录了首个数据所在的地址,随机访问就是通过首地址加上下标乘以类型占的内存空间得到对应下标数据的地址,从而访问得到数据的。
这里我要特别纠正一个“错误”。很多人都认为数组和链表的区别是:“链表适合插入、删除,时间复杂度 O(1);数组适合查找,查找时间复杂度为 O(1)”。
实际上,这种表述是不准确的。数组是适合查找操作,但是查找的时间复杂度并不为 O(1)。即便是排好序的数组,你用二分查找,时间复杂度也是 O(logn)。所以,正确的表述应该是,数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。
低效的“插入”和“删除” 前面概念部分我们提到,数组为了保持内存数据的连续性,会导致插入、删除这两个操作比较低效。现在我们就来详细说一下,究竟为什么会导致低效?又有哪些改进方法呢?
我们先来看插入操作 。
假设数组的长度为 n,现在,如果我们需要将一个数据插入到数组中的第 k 个位置。为了把第 k 个位置腾出来,给新来的数据,我们需要将第 k~n 这部分的元素都顺序地往后挪一位。那插入操作的时间复杂度是多少呢?你可以自己先试着分析一下。
如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为 O(1)。但如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以最坏时间复杂度是 O(n)。 因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为 (1+2+…n)/n=O(n)。
如果数组中的数据是有序的,我们在某个位置插入一个新的元素时,就必须按照刚才的方法搬移 k 之后的数据。但是,如果数组中存储的数据并没有任何规律,数组只是被当作一个存储数据的集合。在这种情况下,如果要将某个数组插入到第 k 个位置,为了避免大规模的数据搬移,我们还有一个简单的办法就是,直接将第 k 位的数据搬移到数组元素的最后,把新的元素直接放入第 k 个位置。
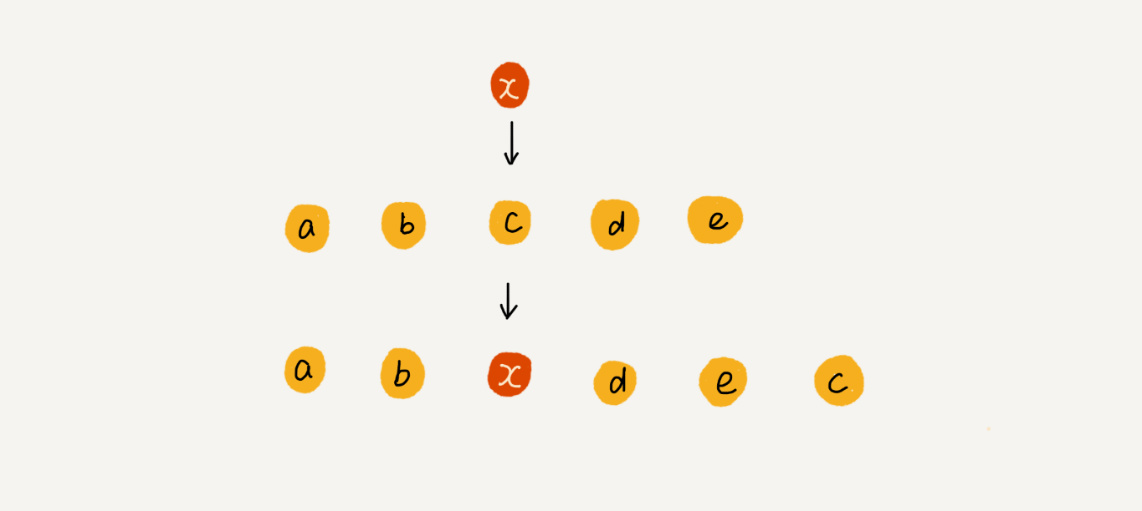
为了更好地理解,我们举一个例子。假设数组 a[10] 中存储了如下 5 个元素:a,b,c,d,e。
我们现在需要将元素 x 插入到第 3 个位置。我们只需要将 c 放入到 a[5],将 a[2] 赋值为 x 即可。最后,数组中的元素如下: a,b,x,d,e,c。
利用这种处理技巧,在特定场景下,在第 k 个位置插入一个元素的时间复杂度就会降为 O(1)。这个处理思想在快排中也会用到,我会在排序那一节具体来讲,这里就说到这儿。
我们再来看删除操作 。
跟插入数据类似,如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了。
和插入类似,如果删除数组末尾的数据,则最好情况时间复杂度为 O(1);如果删除开头的数据,则最坏情况时间复杂度为 O(n);平均情况时间复杂度也为 O(n)。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多呢?
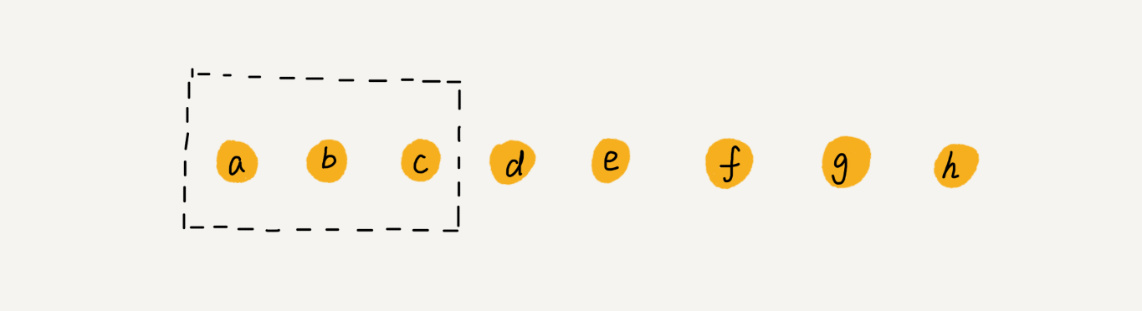
我们继续来看例子。数组 a[10] 中存储了 8 个元素:a,b,c,d,e,f,g,h。现在,我们要依次删除 a,b,c 三个元素。
为了避免 d,e,f,g,h 这几个数据会被搬移三次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
如果你了解 JVM,你会发现,这不就是 JVM 标记清除垃圾回收算法的核心思想吗?没错,数据结构和算法的魅力就在于此,很多时候我们并不是要去死记硬背某个数据结构或者算法,而是要学习它背后的思想和处理技巧,这些东西才是最有价值的 。如果你细心留意,不管是在软件开发还是架构设计中,总能找到某些算法和数据结构的影子。
切片能否完全替代数组? 针对数组类型,很多语言都提供了容器类,比如Go 中的 切片, Java 中的 ArrayList、C++ STL 中的 vector。在项目开发中,什么时候适合用数组,什么时候适合用容器呢?
这里我拿 Go 语言来举例。如果你是Golang 工程师,几乎天天都在用切片,对它应该非常熟悉。那它与数组相比,到底有哪些优势呢?
我个人觉得,切片最大的优势就是支持动态扩容 。
数组本身在定义的时候需要预先指定大小,因为需要分配连续的内存空间。如果我们申请了大小为 10 的数组,当第 11 个数据需要存储到数组中时,我们就需要重新分配一块更大的空间,将原来的数据复制过去,然后再将新的数据插入。
如果使用 切片,我们就完全不需要关心底层的扩容逻辑,切片 已经帮我们实现好了。
不过,这里需要注意一点,因为扩容操作涉及内存申请和数据搬移,是比较耗时的。所以,如果事先能确定需要存储的数据大小,最好在创建 切片 的时候事先指定数据大小 。
比如我们要从数据库中取出 10000 条数据放入 ArrayList。我们看下面这几行代码,你会发现,相比之下,事先指定数据大小可以省掉很多次内存申请和数据搬移操作。
建议在知道或是大概了解范围时,事先为切片分配容量。比如下面这个代码,将会比不事先分配容量节省很多性能:
1 2 3 4 slice := make ([]int , 0 , 1000000 ) for i := 0 ; i < 1000000 ; i++ { slice = append (slice, i) }
作为高级语言编程者,是不是数组就无用武之地了呢?当然不是,如果数据大小事先已知,并且对数据的操作非常简单,用不到 切片 提供的方法,也可以直接使用数组。
但其实对于业务开发,直接使用切片就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
闲话 Golang 的 append 这里突然想插入一点 golang 切片的 append 的东西,我们面试的时候其实很容易被问到 append 一般都是问扩容机制,一般都会答:
没有超出容量不扩容,超出容量会新建一个内存地址把容量扩增为原先的两倍,如果期望容量大于当前容量的两倍就会使用期望容量,最后把老元素拷贝进新内存再追加新元素。
这个回答看似没有问题其实是错的,好一些的回答是:
如果期望容量大于当前容量的两倍就会使用期望容量,否则扩增为原先的两倍;
如果当前切片的长度小于 1024 就会将容量翻倍;
如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
最终新建一个对应容量的内存地址,把老元素拷贝后追加新元素;
其实这个答接近正确的,但并不完全正确,实际扩增容量很可能大于2倍或是1.25倍。上述回答其实是append先进行切片的大致容量确定,就是对应如下append源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func growslice (et *_type, old slice, cap int ) slice newcap := old.cap doublecap := newcap + newcap if cap > doublecap { newcap = cap } else { if old.len < 1024 { newcap = doublecap } else { for 0 < newcap && newcap < cap { newcap += newcap / 4 } if newcap <= 0 { newcap = cap } } }
下面还需要根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会使用如下所示的代码对齐内存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 var overflow bool var lenmem, newlenmem, capmem uintptr switch { case et.size == 1 : lenmem = uintptr (old.len ) newlenmem = uintptr (cap ) capmem = roundupsize(uintptr (newcap)) overflow = uintptr (newcap) > maxAlloc newcap = int (capmem) case et.size == sys.PtrSize: lenmem = uintptr (old.len ) * sys.PtrSize newlenmem = uintptr (cap ) * sys.PtrSize capmem = roundupsize(uintptr (newcap) * sys.PtrSize) overflow = uintptr (newcap) > maxAlloc/sys.PtrSize newcap = int (capmem / sys.PtrSize) case isPowerOfTwo(et.size): ... default : ... }
内存对齐这部分大致说一下,有想了解的可以自行查找。在这段代码中runtime.roundupsizeruntime.class_to_size
1 2 3 4 5 6 7 8 9 10 var class_to_size = [_NumSizeClasses]uint16 { 0 , 8 , 16 , 32 , 48 , 64 , 80 , ..., }
简单总结一下扩容的过程,当我们执行上述代码时,会触发 runtime.growslicearr 切片并传入期望的新容量 5,这时期望分配的内存大小为 40 字节;不过因为切片中的元素大小等于 sys.PtrSize,所以运行时会调用 runtime.roundupsize
我们用一段代码来看它的扩容具体增量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 array := []int {1 , 2 , 3 , 4 , 5 , 6 , 7 } t.Logf("address : %p rray len : %d, array cap : %d" , array, len (array), cap (array)) slice := array[:2 ] t.Logf("address : %p slice len : %d, slice cap : %d" , slice, len (slice), cap (slice)) slice2 := array[:2 :3 ] t.Logf("address : %p slice len : %d, slice cap : %d" , slice2, len (slice2), cap (slice2)) newSlice3 := slice[:1 ] lastI := cap (newSlice3) for i := 0 ; i < 100000 ; i++ { newSlice3 = append (newSlice3, i) capSlice := cap (newSlice3) if capSlice != lastI { t.Logf("address : %p newSlice3 len : %d, slice cap : %d pcp : %s" , newSlice3, len (newSlice3), capSlice, fmt.Sprintf("%d%s" , capSlice*100 /lastI, "%" )) lastI = capSlice }
前三个打印我做了截取的操作,这是我们经常忽略的点,就是如果截取没有确定容量,那么他的容量就是原切片容量。如果指定了容量那么就是你指定的容量。
重头戏是最后一个打印,这里我进行不断的追加,每当容量变化的时候我都会计算一下新容量与旧容量的百分比,扩增10万次。我们来看下结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 === RUN TestGetCapOfSlice kline_test.go:141: address : 0xc00002e180 rray len : 7, array cap : 7 kline_test.go:143: address : 0xc00002e180 slice len : 2, slice cap : 7 kline_test.go:145: address : 0xc00002e180 slice len : 2, slice cap : 3 kline_test.go:147: address : 0xc00002e180 newSlice len : 5, slice cap : 7 kline_test.go:149: address : 0xc00008f650 newSlice2 len : 8, slice cap : 14 kline_test.go:156: address : 0xc00008f6c0 newSlice3 len : 8, slice cap : 14 pcp : 200% kline_test.go:156: address : 0xc00019e540 newSlice3 len : 15, slice cap : 28 pcp : 200% kline_test.go:156: address : 0xc0000f8000 newSlice3 len : 29, slice cap : 56 pcp : 200% kline_test.go:156: address : 0xc00029d880 newSlice3 len : 57, slice cap : 112 pcp : 200% kline_test.go:156: address : 0xc0001f2300 newSlice3 len : 113, slice cap : 224 pcp : 200% kline_test.go:156: address : 0xc000106000 newSlice3 len : 225, slice cap : 512 pcp : 228% kline_test.go:156: address : 0xc00011c000 newSlice3 len : 513, slice cap : 1024 pcp : 200% kline_test.go:156: address : 0xc00023c000 newSlice3 len : 1025, slice cap : 1280 pcp : 125% kline_test.go:156: address : 0xc000246000 newSlice3 len : 1281, slice cap : 1696 pcp : 132% kline_test.go:156: address : 0xc000800000 newSlice3 len : 1697, slice cap : 2304 pcp : 135% kline_test.go:156: address : 0xc0001c4000 newSlice3 len : 2305, slice cap : 3072 pcp : 133% kline_test.go:156: address : 0xc0001ce000 newSlice3 len : 3073, slice cap : 4096 pcp : 133% kline_test.go:156: address : 0xc00027a000 newSlice3 len : 4097, slice cap : 5120 pcp : 125% kline_test.go:156: address : 0xc00035a000 newSlice3 len : 5121, slice cap : 7168 pcp : 140% kline_test.go:156: address : 0xc000812000 newSlice3 len : 7169, slice cap : 9216 pcp : 128% kline_test.go:156: address : 0xc000824000 newSlice3 len : 9217, slice cap : 12288 pcp : 133% kline_test.go:156: address : 0xc00083c000 newSlice3 len : 12289, slice cap : 15360 pcp : 125% kline_test.go:156: address : 0xc00085a000 newSlice3 len : 15361, slice cap : 19456 pcp : 126% kline_test.go:156: address : 0xc000880000 newSlice3 len : 19457, slice cap : 24576 pcp : 126% kline_test.go:156: address : 0xc0008b0000 newSlice3 len : 24577, slice cap : 30720 pcp : 125% kline_test.go:156: address : 0xc0008ec000 newSlice3 len : 30721, slice cap : 38912 pcp : 126% kline_test.go:156: address : 0xc000938000 newSlice3 len : 38913, slice cap : 49152 pcp : 126% kline_test.go:156: address : 0xc000998000 newSlice3 len : 49153, slice cap : 61440 pcp : 125% kline_test.go:156: address : 0xc000800000 newSlice3 len : 61441, slice cap : 76800 pcp : 125% kline_test.go:156: address : 0xc000a10000 newSlice3 len : 76801, slice cap : 96256 pcp : 125% kline_test.go:156: address : 0xc000acc000 newSlice3 len : 96257, slice cap : 120832 pcp : 125% --- PASS: TestGetCapOfSlice (0.00s) PASS
我们可以看到起初在远未达到 512 时确实是按照2倍扩容,但接近512 时直接扩容到了 512 扩容了2.28倍。 在到达1024后,确实第一次是按照1.25倍扩容的,但后续每次都有差异,很多都超过了1.25倍。