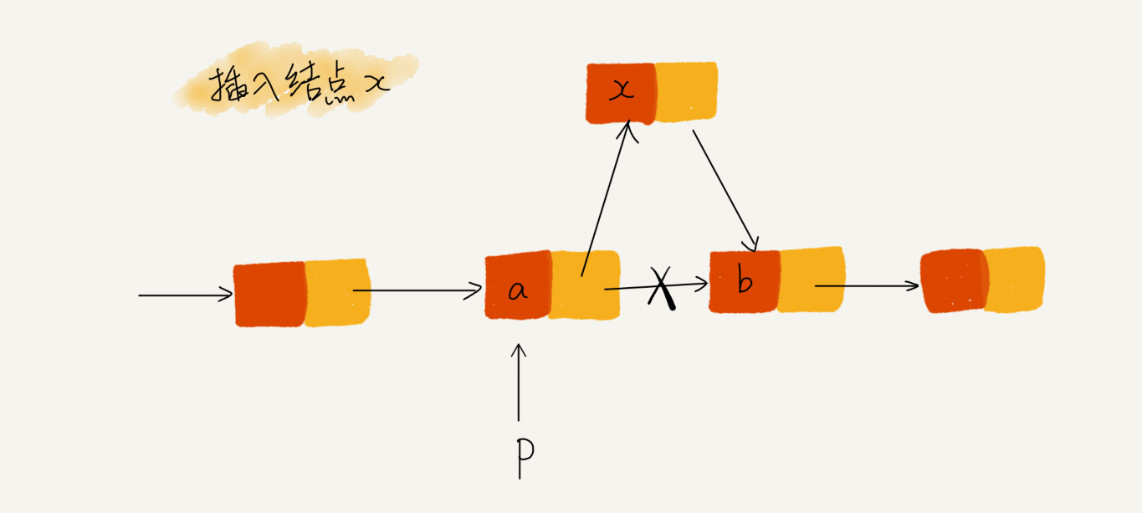
如图所示,我们希望在结点 a 和相邻的结点 b 之间插入结点 x,假设当前指针 p 指向结点 a。如果我们将代码实现变成下面这个样子,就会发生指针丢失和内存泄露。
1 2 3
p.next = &x // 将 p 的 next 指针指向 x 结点; x.next = p.next // 将 x 的结点的 next 指针指向 b 结点;
p.next 指针在完成第一步操作之后,已经不再指向结点 b 了,而是指向结点 x。第 2 行代码相当于将 x 赋值给 x.next,自己指向自己。因此,整个链表也就断成了两半,从结点 b 往后的所有结点都无法访问到了。
对于有些语言来说,比如 C 语言,内存管理是由程序员负责的,如果没有手动释放结点对应的内存空间,就会产生内存泄露。所以,我们插入结点时,一定要注意操作的顺序,要先将结点 x 的 next 指针指向结点 b,再把结点 a 的 next 指针指向结点 x,这样才不会丢失指针,导致内存泄漏。所以,对于刚刚的插入代码,我们只需要把第 1 行和第 2 行代码的顺序颠倒一下就可以了。
同理,删除链表结点时,也一定要记得手动释放内存空间,否则,也会出现内存泄漏的问题。当然,对于像 Go 这种自动管理内存的编程语言来说,就不需要考虑这么多了。
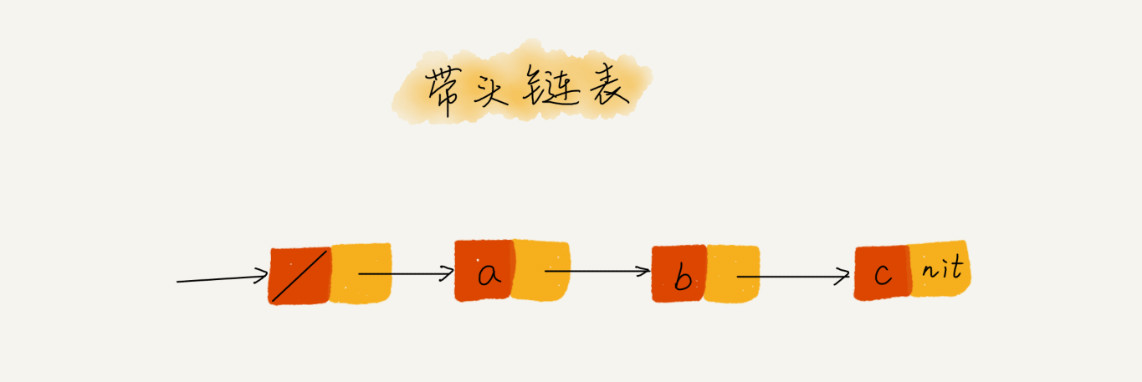
技巧三:利用哨兵简化实现难度
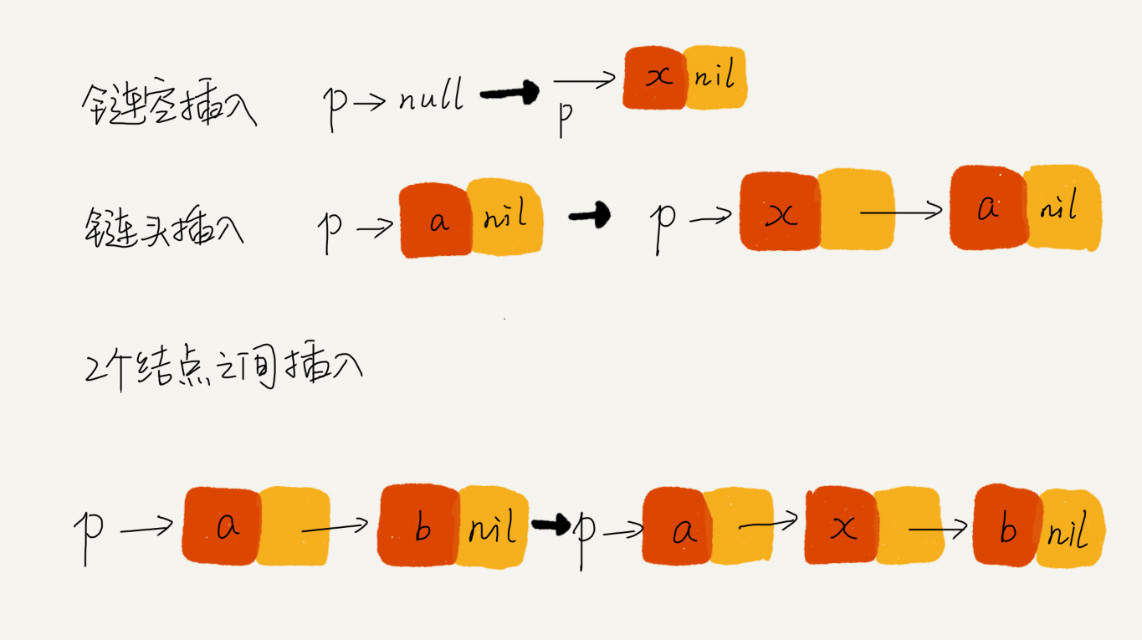
首先,我们先来回顾一下单链表的插入和删除操作。如果我们在结点 p 后面插入一个新的结点,只需要下面两行代码就可以搞定。
1 2
new_node.next = p.next p.next = &new_node
即先把新结点指向p 的后结点,再把p的后结点指向新结点,千万不要写反顺序了哦。
但是,当我们要向一个空链表中插入第一个结点,刚刚的逻辑就不能用了。我们需要进行下面这样的特殊处理,其中 head 表示链表的头结点。所以,从这段代码,我们可以发现,对于单链表的插入操作,第一个结点和其他结点的插入逻辑是不一样的。
1 2 3
if head == nil{ head = new_node }
。如果要删除结点 p 的后继结点,我们只需要一行代码就可以搞定。
1 2
p.next = p.next.next
但是,如果我们要删除的链表中只剩下最后一个结点,前面的删除代码就不 work 了,因为找不到前节点p 。跟插入类似,我们也需要对于这种情况特殊处理。写成代码是这样子的:
// Element is an element of a linked list. type Element struct { // Next and previous pointers in the doubly-linked list of elements. // To simplify the implementation, internally a list l is implemented // as a ring, such that &l.root is both the next element of the last // list element (l.Back()) and the previous element of the first list // element (l.Front()). next, prev *Element
// The list to which this element belongs. list *List
// The value stored with this element. Value interface{} }
// Next returns the next list element or nil. func(e *Element)Next() *Element { if p := e.next; e.list != nil && p != &e.list.root { return p } returnnil }
// Prev returns the previous list element or nil. func(e *Element)Prev() *Element { if p := e.prev; e.list != nil && p != &e.list.root { return p } returnnil }
// List represents a doubly linked list. // The zero value for List is an empty list ready to use. type List struct { root Element // sentinel list element, only &root, root.prev, and root.next are used lenint// current list length excluding (this) sentinel element }
// Init initializes or clears list l. func(l *List)Init() *List { l.root.next = &l.root l.root.prev = &l.root l.len = 0 return l }
// New returns an initialized list. funcNew() *List { returnnew(List).Init() }
// Len returns the number of elements of list l. // The complexity is O(1). func(l *List)Len()int { return l.len }
// Front returns the first element of list l or nil if the list is empty. func(l *List)Front() *Element { if l.len == 0 { returnnil } return l.root.next }
// Back returns the last element of list l or nil if the list is empty. func(l *List)Back() *Element { if l.len == 0 { returnnil } return l.root.prev }
// lazyInit lazily initializes a zero List value. func(l *List)lazyInit() { if l.root.next == nil { l.Init() } }
// insert inserts e after at, increments l.len, and returns e. func(l *List)insert(e, at *Element) *Element { e.prev = at e.next = at.next e.prev.next = e e.next.prev = e e.list = l l.len++ return e }
// insertValue is a convenience wrapper for insert(&Element{Value: v}, at). func(l *List)insertValue(v interface{}, at *Element) *Element { return l.insert(&Element{Value: v}, at) }
// remove removes e from its list, decrements l.len, and returns e. func(l *List)remove(e *Element) *Element { e.prev.next = e.next e.next.prev = e.prev e.next = nil// avoid memory leaks e.prev = nil// avoid memory leaks e.list = nil l.len-- return e }
// move moves e to next to at and returns e. func(l *List)move(e, at *Element) *Element { if e == at { return e } e.prev.next = e.next e.next.prev = e.prev
e.prev = at e.next = at.next e.prev.next = e e.next.prev = e
return e }
// Remove removes e from l if e is an element of list l. // It returns the element value e.Value. // The element must not be nil. func(l *List)Remove(e *Element)interface{} { if e.list == l { // if e.list == l, l must have been initialized when e was inserted // in l or l == nil (e is a zero Element) and l.remove will crash l.remove(e) } return e.Value }
// PushFront inserts a new element e with value v at the front of list l and returns e. func(l *List)PushFront(v interface{}) *Element { l.lazyInit() return l.insertValue(v, &l.root) }
// PushBack inserts a new element e with value v at the back of list l and returns e. func(l *List)PushBack(v interface{}) *Element { l.lazyInit() return l.insertValue(v, l.root.prev) }
// InsertBefore inserts a new element e with value v immediately before mark and returns e. // If mark is not an element of l, the list is not modified. // The mark must not be nil. func(l *List)InsertBefore(v interface{}, mark *Element) *Element { if mark.list != l { returnnil } // see comment in List.Remove about initialization of l return l.insertValue(v, mark.prev) }
// InsertAfter inserts a new element e with value v immediately after mark and returns e. // If mark is not an element of l, the list is not modified. // The mark must not be nil. func(l *List)InsertAfter(v interface{}, mark *Element) *Element { if mark.list != l { returnnil } // see comment in List.Remove about initialization of l return l.insertValue(v, mark) }
// MoveToFront moves element e to the front of list l. // If e is not an element of l, the list is not modified. // The element must not be nil. func(l *List)MoveToFront(e *Element) { if e.list != l || l.root.next == e { return } // see comment in List.Remove about initialization of l l.move(e, &l.root) }
// MoveToBack moves element e to the back of list l. // If e is not an element of l, the list is not modified. // The element must not be nil. func(l *List)MoveToBack(e *Element) { if e.list != l || l.root.prev == e { return } // see comment in List.Remove about initialization of l l.move(e, l.root.prev) }
// MoveBefore moves element e to its new position before mark. // If e or mark is not an element of l, or e == mark, the list is not modified. // The element and mark must not be nil. func(l *List)MoveBefore(e, mark *Element) { if e.list != l || e == mark || mark.list != l { return } l.move(e, mark.prev) }
// MoveAfter moves element e to its new position after mark. // If e or mark is not an element of l, or e == mark, the list is not modified. // The element and mark must not be nil. func(l *List)MoveAfter(e, mark *Element) { if e.list != l || e == mark || mark.list != l { return } l.move(e, mark) }
// PushBackList inserts a copy of another list at the back of list l. // The lists l and other may be the same. They must not be nil. func(l *List)PushBackList(other *List) { l.lazyInit() for i, e := other.Len(), other.Front(); i > 0; i, e = i-1, e.Next() { l.insertValue(e.Value, l.root.prev) } }
// PushFrontList inserts a copy of another list at the front of list l. // The lists l and other may be the same. They must not be nil. func(l *List)PushFrontList(other *List) { l.lazyInit() for i, e := other.Len(), other.Back(); i > 0; i, e = i-1, e.Prev() { l.insertValue(e.Value, &l.root) } }
//双指针 funcReverseList(head *ListNode) *ListNode { var pre *ListNode cur := head for cur != nil { next := cur.Next cur.Next = pre pre = cur cur = next } return pre }