Golang GMP调度模型
Go 语言的Goroutine其实概念和协程是一致的,我们可以称之为有go特色的协程
为了解决多线程调度器的问题,Go 开发者 Dmitry Vyokov 在已有 G、M 的基础上,引入了 P 处理器,由此产生了当前 Go 中经典的 GMP 调度模型。
P:Processor的缩写,代表一个虚拟的处理器,它维护一个局部的可运行的 G 队列,可以通过 CAS 的方式无锁访问,工作线程 M 优先使用自己的局部运行队列中的 G,只有必要时才会去访问全局运行队列,这大大减少了锁冲突,提高了大量 G 的并发性。每个 G 要想真正运行起来,首先需要被分配一个 P。
如图 1.5 所示,是当前 Go 采用的 GMP 调度模型。可运行的 G 是通过处理器 P 和线程 M 绑定起来的,M 的执行是由操作系统调度器将 M 分配到 CPU 上实现的,Go 运行时调度器负责调度 G 到 M 上执行,主要在用户态运行,跟操作系统调度器在内核态运行相对应。
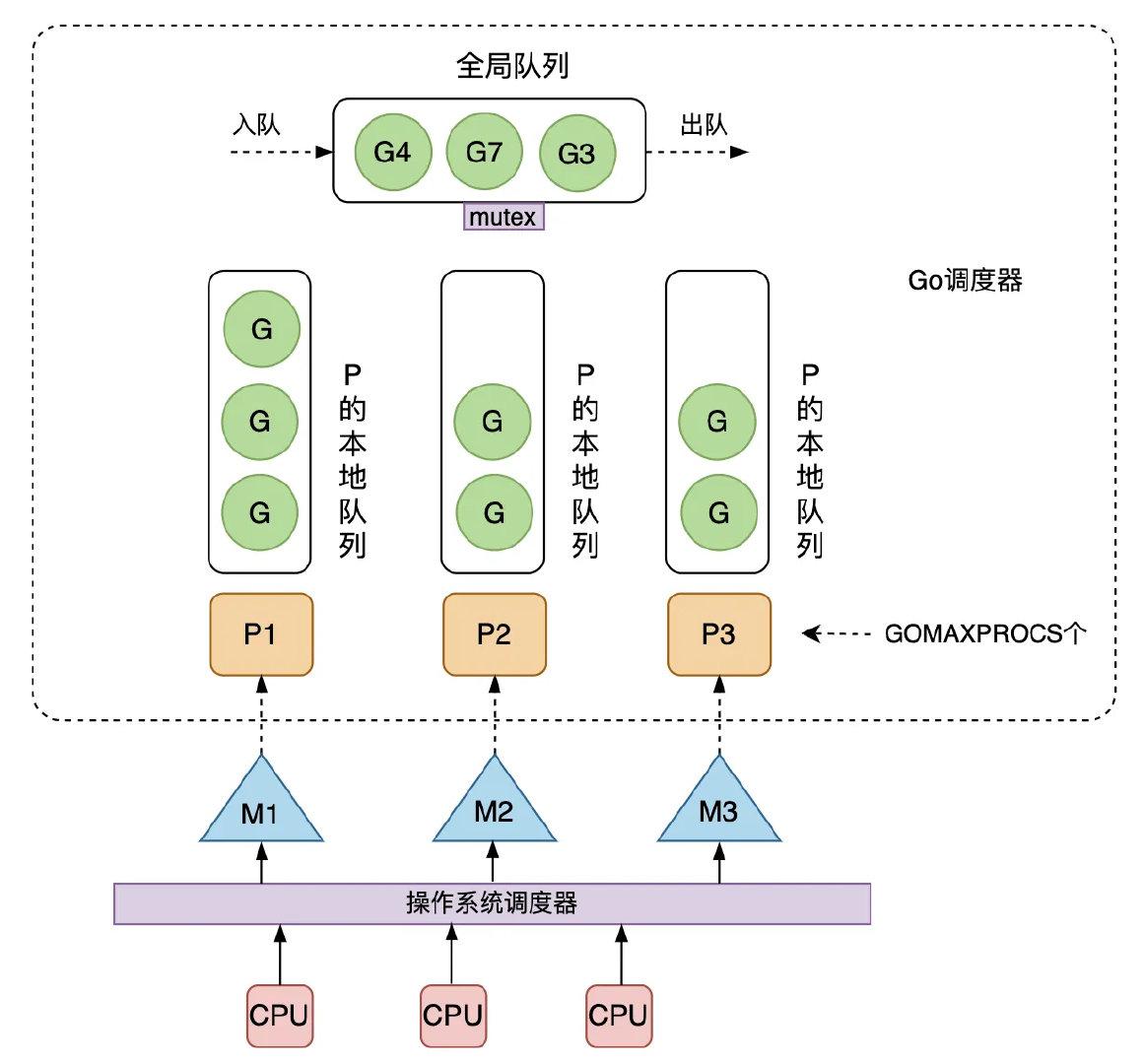
- M 是最重要的结构是一个线程的概念系统会为其分配Cpu资源,用来串联内核态和用户态,Goroutinue的具体代码与M绑定,M又由系统内核调度来为执行代码分配Cpu,当M获取Cpu后与M绑定的goroutinue会开始执行。M的最大数量默认为10000
- P 是为了解决M频繁创建内核态的内存资源不断重新分配产生的资源消耗问题的,作者把本应放入M的内存分配放入到P中,P又固定了和Cpu的数量相同,从而减少了内存重新分配的问题,在满负荷运转下即使M不断的阻塞创建也不会产生内存的重新分配。且P维护了数量256的本地G队列,M只有与P绑定才可以对G进行执行,而M执行优先调度本地队列的G,调度G到M的过程也可说是切换G或G抢占M的过程,无需用锁从而减少了资源消耗,G在本地队列中维护也可减少内存的重新分配问题,即使可能有阻塞抢占的问题G也会优先寻找之前的P。
- G即goroutinue,是我们的执行逻辑代码,当一个G创建后调度器会为其寻找空的P队列来进行加入,p队列会被其绑定的M(如果空闲)不断的获取G来执行。
基于 GMP 模型的 Go 调度器的核心思想是:
\1. 尽可能复用线程 M:避免频繁的线程创建和销毁;
\2. 利用多核并行能力:限制同时运行(不包含阻塞)的 M 线程数为 N,N 等于 CPU 的核心数目,这里通过设置 P 处理器的个数为 GOMAXPROCS 来保证,GOMAXPROCS 一般为 CPU 核数,因为 M 和 P 是一一绑定的,没有找到 P 的 M 会放入空闲 M 列表,没有找到 M 的 P 也会放入空闲 P 列表;
\3. Work Stealing 任务窃取机制:M 优先执行其所绑定的 P 的本地队列的 G,如果本地队列为空,可以从全局队列获取 G 运行,也可以从其他 M 偷取 G 来运行;为了提高并发执行的效率,M 可以从其他 M 绑定的 P 的运行队列偷取 G 执行,这种 GMP 调度模型也叫任务窃取调度模型,这里,任务就是指 G;
\4. Hand Off 交接机制:M 阻塞,会将 M 上 P 的运行队列交给其他 M 执行,交接效率要高,才能提高 Go 程序整体的并发度;
\5. 基于协作的抢占机制:每个真正运行的G,如果不被打断,将会一直运行下去,为了保证公平,防止新创建的 G 一直获取不到 M 执行造成饥饿问题,Go 程序会保证每个 G 运行10ms 就要让出 M,交给其他 G 去执行;
\6. 基于信号的真抢占机制:尽管基于协作的抢占机制能够缓解长时间 GC 导致整个程序无法工作和大多数 Goroutine 饥饿问题,但是还是有部分情况下,Go调度器有无法被抢占的情况,例如,for 循环或者垃圾回收长时间占用线程,为了解决这些问题, Go1.14 引入了基于信号的抢占式调度机制,能够解决 GC 垃圾回收和栈扫描时存在的问题。
几种常见的调度场景
在进入 GMP 调度模型的数据结构和源码之前,可以先用几张图形象的描述下 GMP 调度机制的一些场景,帮助理解 GMP 调度器为了保证公平性、可扩展性、及提高并发效率,所设计的一些机制和策略。
1)创建 G: 正在 M1 上运行的P,有一个G1,通过go func() 创建 G2 后,由于局部性,G2优先放入P的本地队列;
2)G 运行完成后:M1 上的 G1 运行完成后(调用goexit()函数),M1 上运行的 Goroutine 会切换为 G0,G0 负责调度协程的切换(运行schedule() 函数),从 M1 上 P 的本地运行队列获取 G2 去执行(函数execute());注意:这里 G0 是程序启动时的线程 M(也叫M0)的系统栈表示的 G 结构体,负责 M 上 G 的调度;
M 上创建的 G 个数大于本地队列长度时:如果 P 本地队列最多能存 4 个G(实际上是256个),正在 M1 上运行的 G2 要通过go func()创建 6 个G,那么,前 4 个G 放在 P 本地队列中,G2 创建了第 5 个 G(G7)时,P 本地队列中前一半和 G7 一起打乱顺序放入全局队列,P 本地队列剩下的 G 往前移动,G2 创建的第 6 个 G(G8)时,放入 P 本地队列中,因为还有空间;
M 的自旋状态:创建新的 G 时,运行的 G 会尝试唤醒其他空闲的 M 绑定 P 去执行,如果 G2 唤醒了M2,M2 绑定了一个 P2,会先运行 M2 的 G0,这时 M2 没有从 P2 的本地队列中找到 G,会进入自旋状态(spinning),自旋状态的 M2 会尝试从全局空闲线程队列里面获取 G,放到 P2 本地队列去执行,获取的数量满足公式:n = min(len(globrunqsize)/GOMAXPROCS + 1, len(localrunsize/2)),含义是每个P应该从全局队列承担的 G 数量,为了提高效率,不能太多,要给其他 P 留点;
G 发生系统调用时:如果 G 发生系统调度进入阻塞,其所在的 M 也会阻塞,因为会进入内核状态等待系统资源,和 M 绑定的 P 会寻找空闲的 M 执行,这是为了提高效率,不能让 P 本地队列的 G 因所在 M 进入阻塞状态而无法执行;需要说明的是,如果是 M 上的 G 进入 Channel 阻塞,则该 M 不会一起进入阻塞,因为 Channel 数据传输涉及内存拷贝,不涉及系统资源等待;
G 退出系统调用时:如果刚才进入系统调用的 G2 解除了阻塞,其所在的 M1 会寻找 P 去执行,优先找原来的 P,发现没有找到,则其上的 G2 会进入全局队列,等其他 M 获取执行,M1 进入空闲队列;
调度器逻辑图
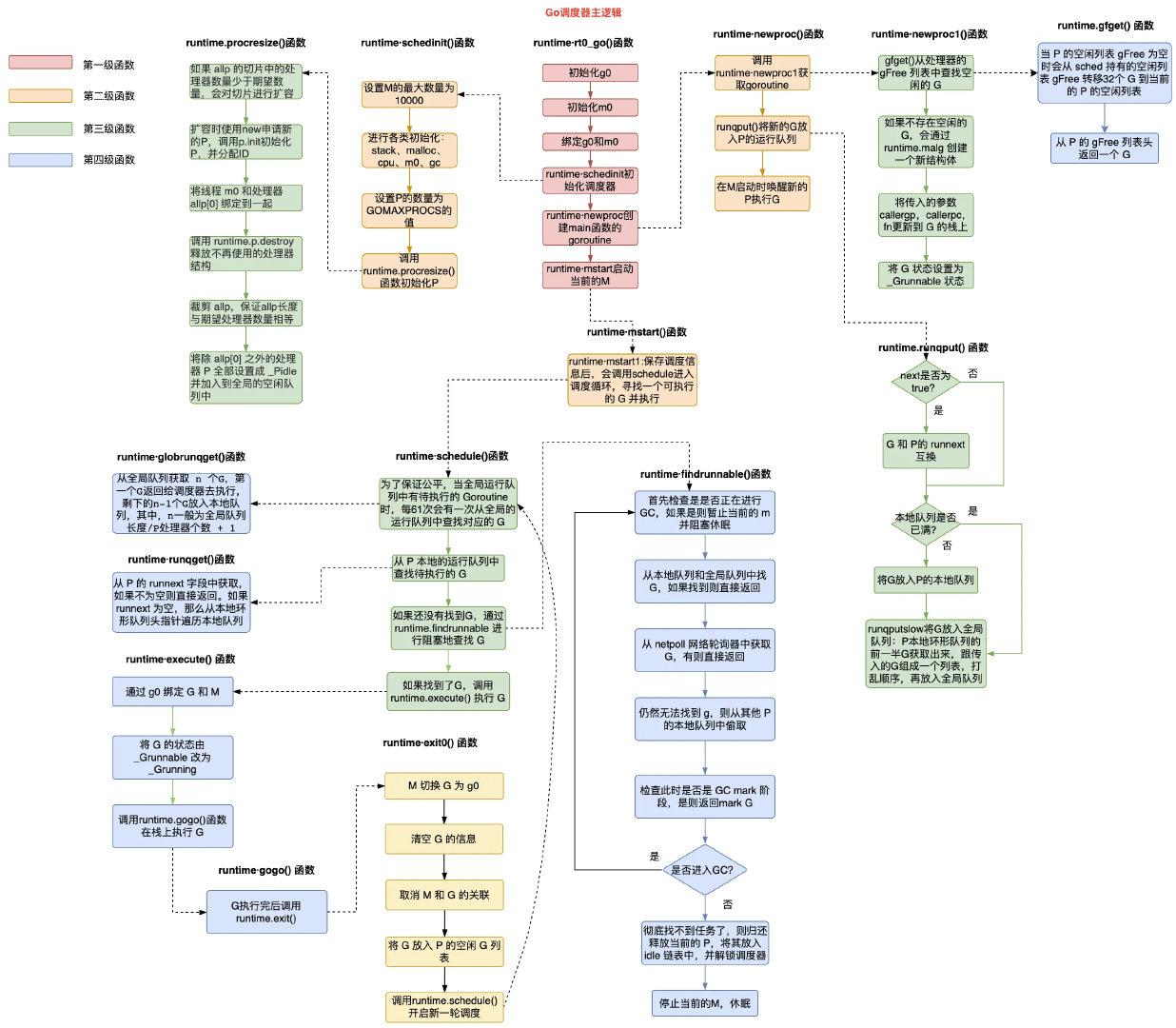
需要说明的是,mcache内存结构原来是在 M 上的,自从引入了 P 之后,就将该结构体移到了P上,这样,就不用每个 M 维护自己的内存分配 mcache,由于 P 在有 M 可以执行时才会移动到其他 M 上去,空闲的 M 无须分配内存,这种灵活性使整体线程的内存分配大大减少。





