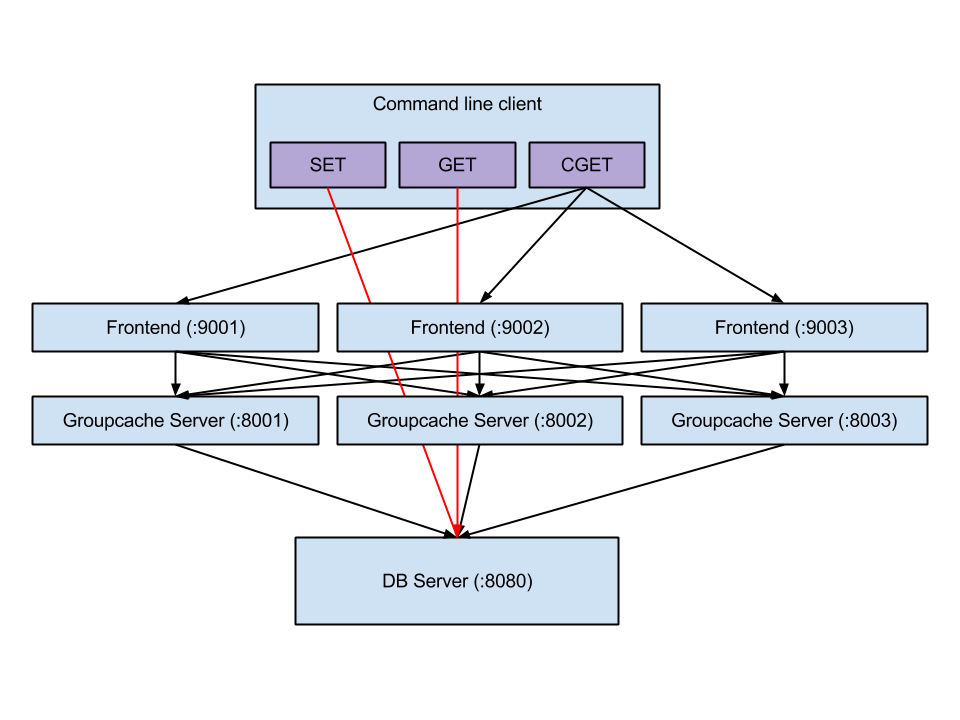
groupcache是memcached作者Brad Fitzpatrick的另一kv cache项目,由于作者转 go 并对go语言情有独钟,所以作者本着‘intended as a replacement for memcached in many cases’ 的设计初衷设计了groupcache 。Redis等其他常用cache实现不同,groupcache并不运行在单独的server上,而是作为library和app运行在同一进程中。所以groupcache既是server也是client。
// A Group is a cache namespace and associated data loaded spread over // a group of 1 or more machines. type Group struct { name string getter Getter peersOnce sync.Once peers PeerPicker cacheBytes int64// limit for sum of mainCache and hotCache size
// mainCache is a cache of the keys for which this process // (amongst its peers) is authoritative. That is, this cache // contains keys which consistent hash on to this process's // peer number. mainCache cache
// hotCache contains keys/values for which this peer is not // authoritative (otherwise they would be in mainCache), but // are popular enough to warrant mirroring in this process to // avoid going over the network to fetch from a peer. Having // a hotCache avoids network hotspotting, where a peer's // network card could become the bottleneck on a popular key. // This cache is used sparingly to maximize the total number // of key/value pairs that can be stored globally. hotCache cache
// loadGroup ensures that each key is only fetched once // (either locally or remotely), regardless of the number of // concurrent callers. loadGroup flightGroup
_ int32// force Stats to be 8-byte aligned on 32-bit platforms
// Stats are statistics on the group. Stats Stats }
peer.go 定义注册节点选择器的方法,在第一次 group get 时会使用节点注册方法进行一次注册。
func(g *Group)Get(ctx context.Context, key string, dest Sink)error { g.peersOnce.Do(g.initPeers) g.Stats.Gets.Add(1) if dest == nil { return errors.New("groupcache: nil dest Sink") } value, cacheHit := g.lookupCache(key)
if cacheHit { g.Stats.CacheHits.Add(1) return setSinkView(dest, value) }
// Optimization to avoid double unmarshalling or copying: keep // track of whether the dest was already populated. One caller // (if local) will set this; the losers will not. The common // case will likely be one caller. destPopulated := false value, destPopulated, err := g.load(ctx, key, dest) if err != nil { return err } if destPopulated { returnnil } return setSinkView(dest, value) }
func(g *Group)lookupCache(key string)(value ByteView, ok bool) { if g.cacheBytes <= 0 { return } value, ok = g.mainCache.get(key) if ok { return } value, ok = g.hotCache.get(key) return }
// load loads key either by invoking the getter locally or by sending it to another machine. func(g *Group)load(ctx context.Context, key string, dest Sink)(value ByteView, destPopulated bool, err error) { g.Stats.Loads.Add(1) viewi, err := g.loadGroup.Do(key, func()(interface{}, error) { // Check the cache again because singleflight can only dedup calls // that overlap concurrently. It's possible for 2 concurrent // requests to miss the cache, resulting in 2 load() calls. An // unfortunate goroutine scheduling would result in this callback // being run twice, serially. If we don't check the cache again, // cache.nbytes would be incremented below even though there will // be only one entry for this key. // // Consider the following serialized event ordering for two // goroutines in which this callback gets called twice for the // same key: // 1: Get("key") // 2: Get("key") // 1: lookupCache("key") // 2: lookupCache("key") // 1: load("key") // 2: load("key") // 1: loadGroup.Do("key", fn) // 1: fn() // 2: loadGroup.Do("key", fn) // 2: fn() if value, cacheHit := g.lookupCache(key); cacheHit { g.Stats.CacheHits.Add(1) return value, nil } g.Stats.LoadsDeduped.Add(1) var value ByteView var err error if peer, ok := g.peers.PickPeer(key); ok { value, err = g.getFromPeer(ctx, peer, key) if err == nil { g.Stats.PeerLoads.Add(1) return value, nil } g.Stats.PeerErrors.Add(1) // TODO(bradfitz): log the peer's error? keep // log of the past few for /groupcachez? It's // probably boring (normal task movement), so not // worth logging I imagine. } value, err = g.getLocally(ctx, key, dest) if err != nil { g.Stats.LocalLoadErrs.Add(1) returnnil, err } g.Stats.LocalLoads.Add(1) destPopulated = true// only one caller of load gets this return value g.populateCache(key, value, &g.mainCache) return value, nil }) if err == nil { value = viewi.(ByteView) } return }
// call is an in-flight or completed Do call type call struct { wg sync.WaitGroup val interface{} err error }
// Group represents a class of work and forms a namespace in which // units of work can be executed with duplicate suppression. type Group struct { mu sync.Mutex // protects m m map[string]*call // lazily initialized }
// Do executes and returns the results of the given function, making // sure that only one execution is in-flight for a given key at a // time. If a duplicate comes in, the duplicate caller waits for the // original to complete and receives the same results. func(g *Group)Do(key string, fn func()(interface{}, error)) (interface{}, error) { g.mu.Lock() if g.m == nil { g.m = make(map[string]*call) } if c, ok := g.m[key]; ok { g.mu.Unlock() c.wg.Wait() return c.val, c.err } c := new(call) c.wg.Add(1) g.m[key] = c g.mu.Unlock()
// The group name must be unique for each getter. funcNewGroup(name string, cacheBytes int64, getter Getter) *Group { return newGroup(name, cacheBytes, getter, nil) }
// If peers is nil, the peerPicker is called via a sync.Once to initialize it. funcnewGroup(name string, cacheBytes int64, getter Getter, peers PeerPicker) *Group { if getter == nil { panic("nil Getter") } mu.Lock() defer mu.Unlock() initPeerServerOnce.Do(callInitPeerServer) if _, dup := groups[name]; dup { panic("duplicate registration of group " + name) } g := &Group{ name: name, getter: getter, peers: peers, cacheBytes: cacheBytes, loadGroup: &singleflight.Group{}, } if fn := newGroupHook; fn != nil { fn(g) } groups[name] = g return g }
// A Getter loads data for a key. type Getter interface { // Get returns the value identified by key, populating dest. // // The returned data must be unversioned. That is, key must // uniquely describe the loaded data, without an implicit // current time, and without relying on cache expiration // mechanisms. Get(ctx context.Context, key string, dest Sink) error }
// A GetterFunc implements Getter with a function. type GetterFunc func(ctx context.Context, key string, dest Sink)error
// values. type cache struct { mu sync.RWMutex nbytes int64// of all keys and values lru *lru.Cache nhit, nget int64 nevict int64// number of evictions }
func(g *Group)populateCache(key string, value ByteView, cache *cache) { if g.cacheBytes <= 0 { return } cache.add(key, value)
// Evict items from cache(s) if necessary. for { mainBytes := g.mainCache.bytes() hotBytes := g.hotCache.bytes() if mainBytes+hotBytes <= g.cacheBytes { return }
// TODO(bradfitz): this is good-enough-for-now logic. // It should be something based on measurements and/or // respecting the costs of different resources. victim := &g.mainCache if hotBytes > mainBytes/8 { victim = &g.hotCache } victim.removeOldest() } }
// Cache is an LRU cache. It is not safe for concurrent access. type Cache struct { // MaxEntries is the maximum number of cache entries before // an item is evicted. Zero means no limit. MaxEntries int
// OnEvicted optionally specifies a callback function to be // executed when an entry is purged from the cache. OnEvicted func(key Key, value interface{})
// A Key may be any value that is comparable. See http://golang.org/ref/spec#Comparison_operators type Key interface{}
type entry struct { key Key value interface{} }
// New creates a new Cache. // If maxEntries is zero, the cache has no limit and it's assumed // that eviction is done by the caller. funcNew(maxEntries int) *Cache { return &Cache{ MaxEntries: maxEntries, ll: list.New(), cache: make(map[interface{}]*list.Element), } }
// Add adds a value to the cache. func(c *Cache)Add(key Key, value interface{}) { if c.cache == nil { c.cache = make(map[interface{}]*list.Element) c.ll = list.New() } if ee, ok := c.cache[key]; ok { c.ll.MoveToFront(ee) ee.Value.(*entry).value = value return } ele := c.ll.PushFront(&entry{key, value}) c.cache[key] = ele if c.MaxEntries != 0 && c.ll.Len() > c.MaxEntries { c.RemoveOldest() } }
// Get looks up a key's value from the cache. func(c *Cache)Get(key Key)(value interface{}, ok bool) { if c.cache == nil { return } if ele, hit := c.cache[key]; hit { c.ll.MoveToFront(ele) return ele.Value.(*entry).value, true } return }
// Remove removes the provided key from the cache. func(c *Cache)Remove(key Key) { if c.cache == nil { return } if ele, hit := c.cache[key]; hit { c.removeElement(ele) } }
// RemoveOldest removes the oldest item from the cache. func(c *Cache)RemoveOldest() { if c.cache == nil { return } ele := c.ll.Back() if ele != nil { c.removeElement(ele) } }
数据存储这块我们了解了,获取数据的时候,作者为了将方法做的通用也做了一个接口Sink,你再翻回上面的 group.Get 的方法会发现接受数据的 dest 参数类型就是一个 Sink 接口,我们来看下这个接口以及作者设计的几个实现类。
Sink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// A Sink receives data from a Get call. // // Implementation of Getter must call exactly one of the Set methods // on success. type Sink interface { // SetString sets the value to s. SetString(s string) error
// SetBytes sets the value to the contents of v. // The caller retains ownership of v. SetBytes(v []byte) error
// SetProto sets the value to the encoded version of m. // The caller retains ownership of m. SetProto(m proto.Message) error
// view returns a frozen view of the bytes for caching. view() (ByteView, error) }
接口实现的几个方法就是set 不同类型的 set ,还有 view 。我们先看 view 方法的函数签名,这个方法其实就是将实现 Sink 类中
资源转换为 ByteView 结构。
在看其他几个 set 相关的函数签名,看之前我们回过头再看 group.Get 这个方法在获取数据成功后都会调用:
1
setSinkView(dest, value)
使用这个方法将value,赋值给 dest 这个 dest 就是我们之前 group.Get 方法中参数传入的 Sink 接收器。
我们看这个 setSinkView 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
funcsetSinkView(s Sink, v ByteView)error { // A viewSetter is a Sink that can also receive its value from // a ByteView. This is a fast path to minimize copies when the // item was already cached locally in memory (where it's // cached as a ByteView) type viewSetter interface { setView(v ByteView) error } if vs, ok := s.(viewSetter); ok { return vs.setView(v) } if v.b != nil { return s.SetBytes(v.b) } return s.SetString(v.s) }
// A ByteView holds an immutable view of bytes. // Internally it wraps either a []byte or a string, // but that detail is invisible to callers. // // A ByteView is meant to be used as a value type, not // a pointer (like a time.Time). type ByteView struct { // If b is non-nil, b is used, else s is used. b []byte s string }
// HTTPPool implements PeerPicker for a pool of HTTP peers. type HTTPPool struct { // Context optionally specifies a context for the server to use when it // receives a request. // If nil, the server uses the request's context Context func(*http.Request)context.Context
// Transport optionally specifies an http.RoundTripper for the client // to use when it makes a request. // If nil, the client uses http.DefaultTransport. Transport func(context.Context)http.RoundTripper
// this peer's base URL, e.g. "https://example.net:8000" self string
// opts specifies the options. opts HTTPPoolOptions
mu sync.Mutex // guards peers and httpGetters peers *consistenthash.Map httpGetters map[string]*httpGetter // keyed by e.g. "http://10.0.0.2:8008" }
// HTTPPoolOptions are the configurations of a HTTPPool. type HTTPPoolOptions struct { // BasePath specifies the HTTP path that will serve groupcache requests. // If blank, it defaults to "/_groupcache/". BasePath string
// Replicas specifies the number of key replicas on the consistent hash. // If blank, it defaults to 50. Replicas int
// HashFn specifies the hash function of the consistent hash. // If blank, it defaults to crc32.ChecksumIEEE. HashFn consistenthash.Hash }
// NewHTTPPool initializes an HTTP pool of peers, and registers itself as a PeerPicker. // For convenience, it also registers itself as an http.Handler with http.DefaultServeMux. // The self argument should be a valid base URL that points to the current server, // for example "http://example.net:8000". funcNewHTTPPool(self string) *HTTPPool { p := NewHTTPPoolOpts(self, nil) http.Handle(p.opts.BasePath, p) return p }
var httpPoolMade bool
// NewHTTPPoolOpts initializes an HTTP pool of peers with the given options. // Unlike NewHTTPPool, this function does not register the created pool as an HTTP handler. // The returned *HTTPPool implements http.Handler and must be registered using http.Handle. funcNewHTTPPoolOpts(self string, o *HTTPPoolOptions) *HTTPPool { if httpPoolMade { panic("groupcache: NewHTTPPool must be called only once") } httpPoolMade = true
p := &HTTPPool{ self: self, httpGetters: make(map[string]*httpGetter), } if o != nil { p.opts = *o } if p.opts.BasePath == "" { p.opts.BasePath = defaultBasePath } if p.opts.Replicas == 0 { p.opts.Replicas = defaultReplicas } p.peers = consistenthash.New(p.opts.Replicas, p.opts.HashFn)
RegisterPeerPicker(func()PeerPicker { return p }) return p }
// Fetch the value for this group/key. group := GetGroup(groupName) if group == nil { http.Error(w, "no such group: "+groupName, http.StatusNotFound) return } var ctx context.Context if p.Context != nil { ctx = p.Context(r) } else { ctx = r.Context() }
group.Stats.ServerRequests.Add(1) var value []byte err := group.Get(ctx, key, AllocatingByteSliceSink(&value)) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return }
// Write the value to the response body as a proto message. body, err := proto.Marshal(&pb.GetResponse{Value: value}) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/x-protobuf") w.Write(body) }
// Set updates the pool's list of peers. // Each peer value should be a valid base URL, // for example "http://example.net:8000". func(p *HTTPPool)Set(peers ...string) { p.mu.Lock() defer p.mu.Unlock() p.peers = consistenthash.New(p.opts.Replicas, p.opts.HashFn) p.peers.Add(peers...) p.httpGetters = make(map[string]*httpGetter, len(peers)) for _, peer := range peers { p.httpGetters[peer] = &httpGetter{transport: p.Transport, baseURL: peer + p.opts.BasePath} } }
func(g *Group)getFromPeer(ctx context.Context, peer ProtoGetter, key string)(ByteView, error) { req := &pb.GetRequest{ Group: &g.name, Key: &key, } res := &pb.GetResponse{} err := peer.Get(ctx, req, res) if err != nil { return ByteView{}, err } value := ByteView{b: res.Value} // TODO(bradfitz): use res.MinuteQps or something smart to // conditionally populate hotCache. For now just do it some // percentage of the time. if rand.Intn(10) == 0 { g.populateCache(key, value, &g.hotCache) } return value, nil }
可以看到入参 peer 是一个 ProtoGetter 的接口,我们来看这个接口:
1 2 3 4 5
// ProtoGetter is the interface that must be implemented by a peer. type ProtoGetter interface { Get(ctx context.Context, in *pb.GetRequest, out *pb.GetResponse) error }
if peer, ok := g.peers.PickPeer(key); ok { value, err = g.getFromPeer(ctx, peer, key) if err == nil { g.Stats.PeerLoads.Add(1) return value, nil } g.Stats.PeerErrors.Add(1) // TODO(bradfitz): log the peer's error? keep // log of the past few for /groupcachez? It's // probably boring (normal task movement), so not // worth logging I imagine. }
可以看到这个 peer 参数其实是通过g.peers.PickPeer这个方法获取到的,那我们想看这个方法就要先看这个 group 中的 peers 结构是啥:
// The group name must be unique for each getter. funcNewGroup(name string, cacheBytes int64, getter Getter) *Group { return newGroup(name, cacheBytes, getter, nil) }
// If peers is nil, the peerPicker is called via a sync.Once to initialize it. funcnewGroup(name string, cacheBytes int64, getter Getter, peers PeerPicker) *Group {
// RegisterPeerPicker registers the peer initialization function. // It is called once, when the first group is created. // Either RegisterPeerPicker or RegisterPerGroupPeerPicker should be // called exactly once, but not both. funcRegisterPeerPicker(fn func()PeerPicker) { if portPicker != nil { panic("RegisterPeerPicker called more than once") } portPicker = func(_ string)PeerPicker { return fn() } }
var ( peerAddrs = flag.String("test_peer_addrs", "", "Comma-separated list of peer addresses; used by TestHTTPPool") peerIndex = flag.Int("test_peer_index", -1, "Index of which peer this child is; used by TestHTTPPool") peerChild = flag.Bool("test_peer_child", false, "True if running as a child process; used by TestHTTPPool") )
funcTestHTTPPool(t *testing.T) { if *peerChild { beChildForTestHTTPPool() os.Exit(0) }
const ( nChild = 4 nGets = 100 )
var childAddr []string for i := 0; i < nChild; i++ { childAddr = append(childAddr, pickFreeAddr(t)) }
var cmds []*exec.Cmd var wg sync.WaitGroup for i := 0; i < nChild; i++ { cmd := exec.Command(os.Args[0], "--test.run=TestHTTPPool", "--test_peer_child", "--test_peer_addrs="+strings.Join(childAddr, ","), "--test_peer_index="+strconv.Itoa(i), ) cmds = append(cmds, cmd) wg.Add(1) if err := cmd.Start(); err != nil { t.Fatal("failed to start child process: ", err) } go awaitAddrReady(t, childAddr[i], &wg) } deferfunc() { for i := 0; i < nChild; i++ { if cmds[i].Process != nil { cmds[i].Process.Kill() } } }() wg.Wait()
// Use a dummy self address so that we don't handle gets in-process. p := NewHTTPPool("should-be-ignored") p.Set(addrToURL(childAddr)...)
// Dummy getter function. Gets should go to children only. // The only time this process will handle a get is when the // children can't be contacted for some reason. getter := GetterFunc(func(ctx context.Context, key string, dest Sink)error { return errors.New("parent getter called; something's wrong") }) g := NewGroup("httpPoolTest", 1<<20, getter)
for _, key := range testKeys(nGets) { var value string if err := g.Get(context.TODO(), key, StringSink(&value)); err != nil { t.Fatal(err) } if suffix := ":" + key; !strings.HasSuffix(value, suffix) { t.Errorf("Get(%q) = %q, want value ending in %q", key, value, suffix) } t.Logf("Get key=%q, value=%q (peer:key)", key, value) } }