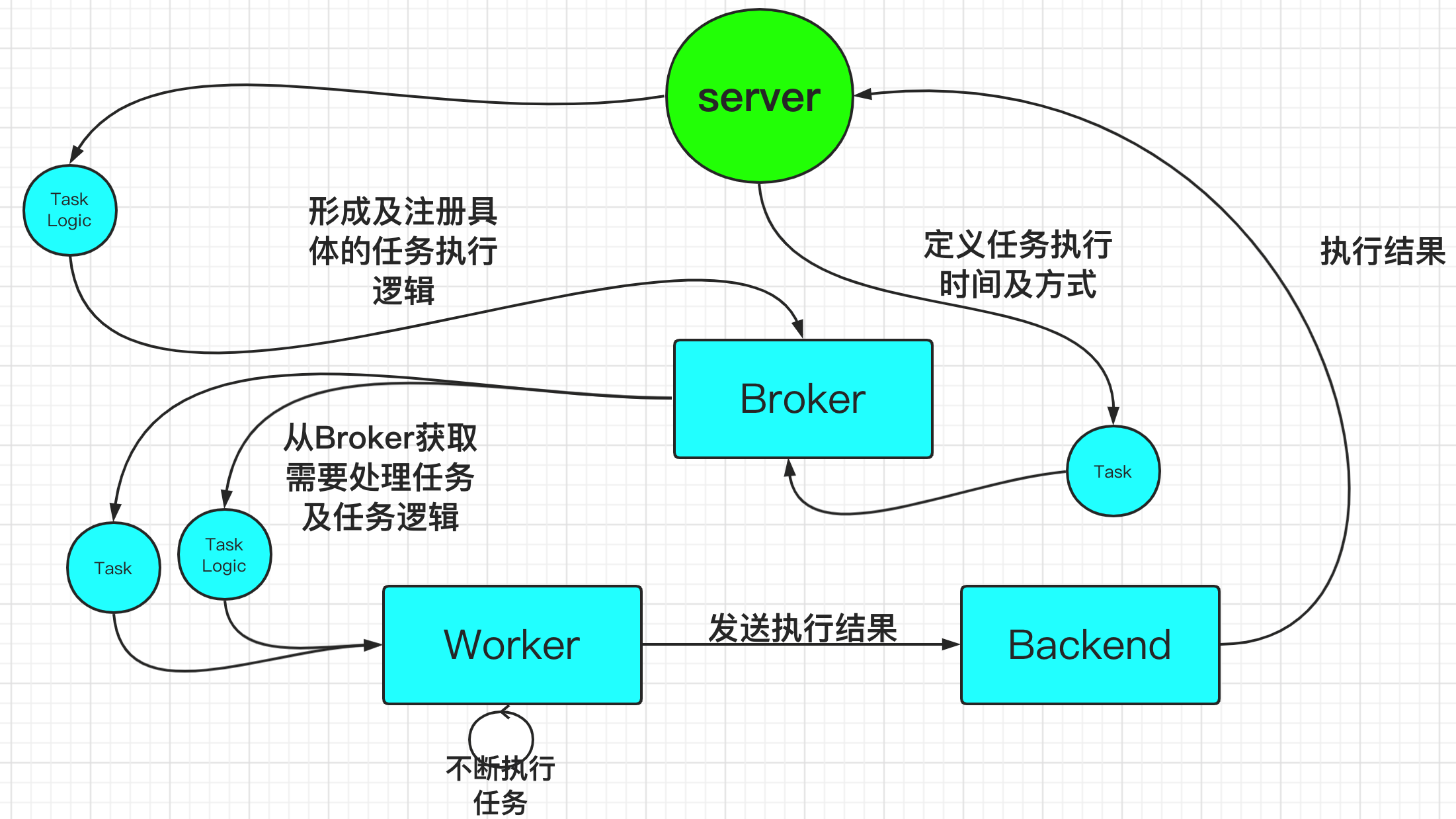
Server 结构是Machinery的业务主体,其中包含了配置,任务逻辑,Broker,Backend其结构如下:
1 2 3 4 5 6 7 8 9
// Server is the main Machinery object and stores all configuration // All the tasks workers process are registered against the server type Server struct { config *config.Config registeredTasks map[string]interface{} broker brokersiface.Broker backend backendsiface.Backend }
// RegisterTasks registers all tasks at once func(server *Server)RegisterTasks(namedTaskFuncs map[string]interface{})error { for _, task := range namedTaskFuncs { if err := tasks.ValidateTask(task); err != nil { return err } }
for k, v := range namedTaskFuncs { server.registeredTasks.Store(k, v) }
// ValidateTask validates task function using reflection and makes sure // it has a proper signature. Functions used as tasks must return at least a // single value and the last return type must be error funcValidateTask(task interface{})error { v := reflect.ValueOf(task) t := v.Type()
// Task must be a function if t.Kind() != reflect.Func { return ErrTaskMustBeFunc }
// Task must return at least a single value if t.NumOut() < 1 { return ErrTaskReturnsNoValue }
// Last return value must be error lastReturnType := t.Out(t.NumOut() - 1) errorInterface := reflect.TypeOf((*error)(nil)).Elem() if !lastReturnType.Implements(errorInterface) { return ErrLastReturnValueMustBeError }
// Worker represents a single worker process type Worker struct { server *Server ConsumerTag string Concurrency int Queue string errorHandler func(err error) preTaskHandler func(*tasks.Signature) postTaskHandler func(*tasks.Signature) preConsumeHandler func(*Worker)bool }
// Launch starts a new worker process. The worker subscribes // to the default queue and processes incoming registered tasks func(worker *Worker)Launch()error {}
// LaunchAsync is a non blocking version of Launch func(worker *Worker)LaunchAsync(errorsChan chan<- error) {}
// CustomQueue returns Custom Queue of the running worker process func(worker *Worker)CustomQueue()string {}
// Quit tears down the running worker process func(worker *Worker)Quit() {}
// Process handles received tasks and triggers success/error callbacks func(worker *Worker)Process(signature *tasks.Signature)error {}
// retryTask decrements RetryCount counter and republishes the task to the queue func(worker *Worker)taskRetry(signature *tasks.Signature)error {}
// taskRetryIn republishes the task to the queue with ETA of now + retryIn.Seconds() func(worker *Worker)retryTaskIn(signature *tasks.Signature, retryIn time.Duration)error {}
// taskSucceeded updates the task state and triggers success callbacks or a // chord callback if this was the last task of a group with a chord callback func(worker *Worker)taskSucceeded(signature *tasks.Signature, taskResults []*tasks.TaskResult)error {}
// taskFailed updates the task state and triggers error callbacks func(worker *Worker)taskFailed(signature *tasks.Signature, taskErr error)error {}
// Returns true if the worker uses AMQP backend func(worker *Worker)hasAMQPBackend()bool {}
// SetErrorHandler sets a custom error handler for task errors // A default behavior is just to log the error after all the retry attempts fail func(worker *Worker)SetErrorHandler(handler func(err error)) {}
//SetPreTaskHandler sets a custom handler func before a job is started func(worker *Worker)SetPreTaskHandler(handler func(*tasks.Signature)) {}
//SetPostTaskHandler sets a custom handler for the end of a job func(worker *Worker)SetPostTaskHandler(handler func(*tasks.Signature)) {}
//SetPreConsumeHandler sets a custom handler for the end of a job func(worker *Worker)SetPreConsumeHandler(handler func(*Worker)bool) {}
// Launch starts a new worker process. The worker subscribes // to the default queue and processes incoming registered tasks func(worker *Worker)Launch()error { errorsChan := make(chan error)
worker.LaunchAsync(errorsChan)
return <-errorsChan }
// LaunchAsync is a non blocking version of Launch func(worker *Worker)LaunchAsync(errorsChan chan<- error) { cnf := worker.server.GetConfig() broker := worker.server.GetBroker()
// Log some useful information about worker configuration log.INFO.Printf("Launching a worker with the following settings:") log.INFO.Printf("- Broker: %s", RedactURL(cnf.Broker)) if worker.Queue == "" { log.INFO.Printf("- DefaultQueue: %s", cnf.DefaultQueue) } else { log.INFO.Printf("- CustomQueue: %s", worker.Queue) } log.INFO.Printf("- ResultBackend: %s", RedactURL(cnf.ResultBackend)) if cnf.AMQP != nil { log.INFO.Printf("- AMQP: %s", cnf.AMQP.Exchange) log.INFO.Printf(" - Exchange: %s", cnf.AMQP.Exchange) log.INFO.Printf(" - ExchangeType: %s", cnf.AMQP.ExchangeType) log.INFO.Printf(" - BindingKey: %s", cnf.AMQP.BindingKey) log.INFO.Printf(" - PrefetchCount: %d", cnf.AMQP.PrefetchCount) }
var signalWG sync.WaitGroup // Goroutine to start broker consumption and handle retries when broker connection dies gofunc() { for { retry, err := broker.StartConsuming(worker.ConsumerTag, worker.Concurrency, worker)
if retry { if worker.errorHandler != nil { worker.errorHandler(err) } else { log.WARNING.Printf("Broker failed with error: %s", err) } } else { signalWG.Wait() errorsChan <- err // stop the goroutine return } } }() if !cnf.NoUnixSignals { sig := make(chan os.Signal, 1) signal.Notify(sig, os.Interrupt, syscall.SIGTERM) var signalsReceived uint
// Goroutine Handle SIGINT and SIGTERM signals gofunc() { for s := range sig { log.WARNING.Printf("Signal received: %v", s) signalsReceived++
if signalsReceived < 2 { // After first Ctrl+C start quitting the worker gracefully log.WARNING.Print("Waiting for running tasks to finish before shutting down") signalWG.Add(1) gofunc() { worker.Quit() errorsChan <- ErrWorkerQuitGracefully signalWG.Done() }() } else { // Abort the program when user hits Ctrl+C second time in a row errorsChan <- ErrWorkerQuitAbruptly } } }() } }
// Process handles received tasks and triggers success/error callbacks func(worker *Worker)Process(signature *tasks.Signature)error { // If the task is not registered with this worker, do not continue // but only return nil as we do not want to restart the worker process if !worker.server.IsTaskRegistered(signature.Name) { returnnil }
// Update task state to RECEIVED if err = worker.server.GetBackend().SetStateReceived(signature); err != nil { return fmt.Errorf("Set state to 'received' for task %s returned error: %s", signature.UUID, err) }
// Prepare task for processing task, err := tasks.NewWithSignature(taskFunc, signature) // if this failed, it means the task is malformed, probably has invalid // signature, go directly to task failed without checking whether to retry if err != nil { worker.taskFailed(signature, err) return err }
// try to extract trace span from headers and add it to the function context // so it can be used inside the function if it has context.Context as the first // argument. Start a new span if it isn't found. taskSpan := tracing.StartSpanFromHeaders(signature.Headers, signature.Name) tracing.AnnotateSpanWithSignatureInfo(taskSpan, signature) task.Context = opentracing.ContextWithSpan(task.Context, taskSpan)
// Update task state to STARTED if err = worker.server.GetBackend().SetStateStarted(signature); err != nil { return fmt.Errorf("Set state to 'started' for task %s returned error: %s", signature.UUID, err) }
//Run handler before the task is called if worker.preTaskHandler != nil { worker.preTaskHandler(signature) }
//Defer run handler for the end of the task if worker.postTaskHandler != nil { defer worker.postTaskHandler(signature) }
// Call the task results, err := task.Call() if err != nil { // If a tasks.ErrRetryTaskLater was returned from the task, // retry the task after specified duration retriableErr, ok := interface{}(err).(tasks.ErrRetryTaskLater) if ok { return worker.retryTaskIn(signature, retriableErr.RetryIn()) }
// Otherwise, execute default retry logic based on signature.RetryCount // and signature.RetryTimeout values if signature.RetryCount > 0 { return worker.taskRetry(signature) }
// Signature represents a single task invocation type Signature struct { UUID string Name string RoutingKey string ETA *time.Time GroupUUID string GroupTaskCount int Args []Arg Headers Headers Priority uint8 Immutable bool RetryCount int RetryTimeout int OnSuccess []*Signature OnError []*Signature ChordCallback *Signature //MessageGroupId for Broker, e.g. SQS BrokerMessageGroupId string //ReceiptHandle of SQS Message SQSReceiptHandle string // StopTaskDeletionOnError used with sqs when we want to send failed messages to dlq, // and don't want machinery to delete from source queue StopTaskDeletionOnError bool // IgnoreWhenTaskNotRegistered auto removes the request when there is no handeler available // When this is true a task with no handler will be ignored and not placed back in the queue IgnoreWhenTaskNotRegistered bool }
// AdjustRoutingKey makes sure the routing key is correct. // If the routing key is an empty string: // a) set it to binding key for direct exchange type // b) set it to default queue name func(b *Broker)AdjustRoutingKey(s *tasks.Signature) { if s.RoutingKey != "" { return }
// Arg represents a single argument passed to invocation fo a task type Arg struct { Name string`bson:"name"` Type string`bson:"type"` Value interface{} `bson:"value"` }
// Task wraps a signature and methods used to reflect task arguments and // return values after invoking the task type Task struct { TaskFunc reflect.Value UseContext bool Context context.Context Args []reflect.Value }
// New tries to use reflection to convert the function and arguments // into a reflect.Value and prepare it for invocation funcNew(taskFunc interface{}, args []Arg)(*Task, error) { task := &Task{ TaskFunc: reflect.ValueOf(taskFunc), Context: context.Background(), }
taskFuncType := reflect.TypeOf(taskFunc) if taskFuncType.NumIn() > 0 { arg0Type := taskFuncType.In(0) if IsContextType(arg0Type) { task.UseContext = true } }
for i, arg := range args { argValue, err := ReflectValue(arg.Type, arg.Value) if err != nil { return err } argValues[i] = argValue }
t.Args = argValues returnnil }
// ReflectValue converts interface{} to reflect.Value based on string type funcReflectValue(valueType string, value interface{})(reflect.Value, error) { if strings.HasPrefix(valueType, "[]") { return reflectValues(valueType, value) }
return reflectValue(valueType, value) }
// reflectValue converts interface{} to reflect.Value based on string type // representing a base type (not a slice) funcreflectValue(valueType string, value interface{})(reflect.Value, error) { theType, ok := typesMap[valueType] if !ok { return reflect.Value{}, NewErrUnsupportedType(valueType) } theValue := reflect.New(theType)
// reflectValues converts interface{} to reflect.Value based on string type // representing a slice of values funcreflectValues(valueType string, value interface{})(reflect.Value, error) { theType, ok := typesMap[valueType] if !ok { return reflect.Value{}, NewErrUnsupportedType(valueType) }
// For NULL we return an empty slice if value == nil { return reflect.MakeSlice(theType, 0, 0), nil }
var theValue reflect.Value
// Booleans if theType.String() == "[]bool" { bools := reflect.ValueOf(value)
theValue = reflect.MakeSlice(theType, bools.Len(), bools.Len()) for i := 0; i < bools.Len(); i++ { boolValue, err := getBoolValue(strings.Split(theType.String(), "[]")[1], bools.Index(i).Interface()) if err != nil { return reflect.Value{}, err }
theValue.Index(i).SetBool(boolValue) }
return theValue, nil }
// Integers if strings.HasPrefix(theType.String(), "[]int") { ints := reflect.ValueOf(value)
theValue = reflect.MakeSlice(theType, ints.Len(), ints.Len()) for i := 0; i < ints.Len(); i++ { intValue, err := getIntValue(strings.Split(theType.String(), "[]")[1], ints.Index(i).Interface()) if err != nil { return reflect.Value{}, err }
// Decode the base64 string if the value type is []uint8 or it's alias []byte // See: https://golang.org/pkg/encoding/json/#Marshal // > Array and slice values encode as JSON arrays, except that []byte encodes as a base64-encoded string if reflect.TypeOf(value).String() == "string" { output, err := base64.StdEncoding.DecodeString(value.(string)) if err != nil { return reflect.Value{}, err } value = output }
uints := reflect.ValueOf(value)
theValue = reflect.MakeSlice(theType, uints.Len(), uints.Len()) for i := 0; i < uints.Len(); i++ { uintValue, err := getUintValue(strings.Split(theType.String(), "[]")[1], uints.Index(i).Interface()) if err != nil { return reflect.Value{}, err }
theValue.Index(i).SetUint(uintValue) }
return theValue, nil }
// Floating point numbers if strings.HasPrefix(theType.String(), "[]float") { floats := reflect.ValueOf(value)
theValue = reflect.MakeSlice(theType, floats.Len(), floats.Len()) for i := 0; i < floats.Len(); i++ { floatValue, err := getFloatValue(strings.Split(theType.String(), "[]")[1], floats.Index(i).Interface()) if err != nil { return reflect.Value{}, err }
theValue.Index(i).SetFloat(floatValue) }
return theValue, nil }
// Strings if theType.String() == "[]string" { strs := reflect.ValueOf(value)
theValue = reflect.MakeSlice(theType, strs.Len(), strs.Len()) for i := 0; i < strs.Len(); i++ { strValue, err := getStringValue(strings.Split(theType.String(), "[]")[1], strs.Index(i).Interface()) if err != nil { return reflect.Value{}, err }
// Call attempts to call the task with the supplied arguments. // // `err` is set in the return value in two cases: // 1. The reflected function invocation panics (e.g. due to a mismatched // argument list). // 2. The task func itself returns a non-nil error. func(t *Task)Call()(taskResults []*TaskResult, err error) { // retrieve the span from the task's context and finish it as soon as this function returns if span := opentracing.SpanFromContext(t.Context); span != nil { defer span.Finish() }
deferfunc() { // Recover from panic and set err. if e := recover(); e != nil { switch e := e.(type) { default: err = ErrTaskPanicked case error: err = e casestring: err = errors.New(e) }
// mark the span as failed and dump the error and stack trace to the span if span := opentracing.SpanFromContext(t.Context); span != nil { opentracing_ext.Error.Set(span, true) span.LogFields( opentracing_log.Error(err), opentracing_log.Object("stack", string(debug.Stack())), ) }
// Invoke the task results := t.TaskFunc.Call(args)
// Task must return at least a value iflen(results) == 0 { returnnil, ErrTaskReturnsNoValue }
// Last returned value lastResult := results[len(results)-1]
// If the last returned value is not nil, it has to be of error type, if that // is not the case, return error message, otherwise propagate the task error // to the caller if !lastResult.IsNil() { // If the result implements Retriable interface, return instance of Retriable retriableErrorInterface := reflect.TypeOf((*Retriable)(nil)).Elem() if lastResult.Type().Implements(retriableErrorInterface) { returnnil, lastResult.Interface().(ErrRetryTaskLater) }
// Otherwise, check that the result implements the standard error interface, // if not, return ErrLastReturnValueMustBeError error errorInterface := reflect.TypeOf((*error)(nil)).Elem() if !lastResult.Type().Implements(errorInterface) { returnnil, ErrLastReturnValueMustBeError }
// Return the standard error returnnil, lastResult.Interface().(error) }
// Convert reflect values to task results taskResults = make([]*TaskResult, len(results)-1) for i := 0; i < len(results)-1; i++ { val := results[i].Interface() typeStr := reflect.TypeOf(val).String() taskResults[i] = &TaskResult{ Type: typeStr, Value: val, } }
funcTestRedisRedisWorkerQuitRaceCondition(t *testing.T) { repeat := 3 for i := 0; i < repeat; i++ { redisURL := os.Getenv("REDIS_URL") if redisURL == "" { t.Skip("REDIS_URL is not defined") }
// Check Quit() immediately after LaunchAsync() will shutdown gracefully // and not panic on close(b.stopChan) worker.LaunchAsync(errorsChan) worker.Quit()
if err := <-errorsChan; err != nil { t.Errorf("Error shutting down machinery worker gracefully %+v", err) continue } } }
// BrokerFactory creates a new object of iface.Broker // Currently only AMQP/S broker is supported funcBrokerFactory(cnf *config.Config)(brokeriface.Broker, error) { if strings.HasPrefix(cnf.Broker, "amqp://") { return amqpbroker.New(cnf), nil }
if strings.HasPrefix(cnf.Broker, "amqps://") { return amqpbroker.New(cnf), nil }
if strings.HasPrefix(cnf.Broker, "eager") { return eagerbroker.New(), nil }
if _, ok := os.LookupEnv("DISABLE_STRICT_SQS_CHECK"); ok { //disable SQS name check, so that users can use this with local simulated SQS //where sql broker url might not start with https://sqs
//even when disabling strict SQS naming check, make sure its still a valid http URL if strings.HasPrefix(cnf.Broker, "https://") || strings.HasPrefix(cnf.Broker, "http://") { return sqsbroker.New(cnf), nil } } else { if strings.HasPrefix(cnf.Broker, "https://sqs") { return sqsbroker.New(cnf), nil } }
returnnil, fmt.Errorf("Factory failed with broker URL: %v", cnf.Broker) }
函数也比较清晰我们就不多解释。
Redis的Broker结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// Broker represents a Redis broker type Broker struct { common.Broker common.RedisConnector host string password string db int pool *redis.Pool consumingWG sync.WaitGroup // wait group to make sure whole consumption completes processingWG sync.WaitGroup // use wait group to make sure task processing completes delayedWG sync.WaitGroup // If set, path to a socket file overrides hostname socketPath string redsync *redsync.Redsync redisOnce sync.Once redisDelayedTasksKey string }
// Ping the server to make sure connection is live _, err := conn.Do("PING") if err != nil { b.GetRetryFunc()(b.GetRetryStopChan())
// Return err if retry is still true. // If retry is false, broker.StopConsuming() has been called and // therefore Redis might have been stopped. Return nil exit // StartConsuming() if b.GetRetry() { return b.GetRetry(), err } return b.GetRetry(), errs.ErrConsumerStopped }
// Channel to which we will push tasks ready for processing by worker deliveries := make(chan []byte, concurrency) pool := make(chanstruct{}, concurrency)
// initialize worker pool with maxWorkers workers for i := 0; i < concurrency; i++ { pool <- struct{}{} }
// A receiving goroutine keeps popping messages from the queue by BLPOP // If the message is valid and can be unmarshaled into a proper structure // we send it to the deliveries channel gofunc() {
log.INFO.Print("[*] Waiting for messages. To exit press CTRL+C")
for { select { // A way to stop this goroutine from b.StopConsuming case <-b.GetStopChan(): close(deliveries) return case <-pool: select { case <-b.GetStopChan(): close(deliveries) return default: }
if taskProcessor.PreConsumeHandler() { task, _ := b.nextTask(getQueue(b.GetConfig(), taskProcessor)) //TODO: should this error be ignored? iflen(task) > 0 { deliveries <- task } }
pool <- struct{}{} } } }()
// A goroutine to watch for delayed tasks and push them to deliveries // channel for consumption by the worker b.delayedWG.Add(1) gofunc() { defer b.delayedWG.Done()
for { select { // A way to stop this goroutine from b.StopConsuming case <-b.GetStopChan(): return default: task, err := b.nextDelayedTask(b.redisDelayedTasksKey) if err != nil { continue }
// nextTask pops next available task from the default queue func(b *Broker)nextTask(queue string)(result []byte, err error) { conn := b.open() defer conn.Close()
pollPeriodMilliseconds := 1000// default poll period for normal tasks if b.GetConfig().Redis != nil { configuredPollPeriod := b.GetConfig().Redis.NormalTasksPollPeriod if configuredPollPeriod > 0 { pollPeriodMilliseconds = configuredPollPeriod } } pollPeriod := time.Duration(pollPeriodMilliseconds) * time.Millisecond
// Issue 548: BLPOP expects an integer timeout expresses in seconds. // The call will if the value is a float. Convert to integer using // math.Ceil(): // math.Ceil(0.0) --> 0 (block indefinitely) // math.Ceil(0.2) --> 1 (timeout after 1 second) pollPeriodSeconds := math.Ceil(pollPeriod.Seconds())
// items[0] - the name of the key where an element was popped // items[1] - the value of the popped element iflen(items) != 2 { return []byte{}, redis.ErrNil }
// consume takes delivered messages from the channel and manages a worker pool // to process tasks concurrently func(b *Broker)consume(deliveries <-chan []byte, concurrency int, taskProcessor iface.TaskProcessor)error { errorsChan := make(chan error, concurrency*2) pool := make(chanstruct{}, concurrency)
// init pool for Worker tasks execution, as many slots as Worker concurrency param gofunc() { for i := 0; i < concurrency; i++ { pool <- struct{}{} } }()
for { select { case err := <-errorsChan: return err case d, open := <-deliveries: if !open { returnnil } if concurrency > 0 { // get execution slot from pool (blocks until one is available) select { case <-b.GetStopChan(): b.requeueMessage(d, taskProcessor) continue case <-pool: } }
b.processingWG.Add(1)
// Consume the task inside a goroutine so multiple tasks // can be processed concurrently gofunc() { if err := b.consumeOne(d, taskProcessor); err != nil { errorsChan <- err }
b.processingWG.Done()
if concurrency > 0 { // give slot back to pool pool <- struct{}{} } }() } } }
// consumeOne processes a single message using TaskProcessor func(b *Broker)consumeOne(delivery []byte, taskProcessor iface.TaskProcessor)error { signature := new(tasks.Signature) decoder := json.NewDecoder(bytes.NewReader(delivery)) decoder.UseNumber() if err := decoder.Decode(signature); err != nil { return errs.NewErrCouldNotUnmarshalTaskSignature(delivery, err) }
// If the task is not registered, we requeue it, // there might be different workers for processing specific tasks if !b.IsTaskRegistered(signature.Name) { if signature.IgnoreWhenTaskNotRegistered { returnnil } log.INFO.Printf("Task not registered with this worker. Requeuing message: %s", delivery) b.requeueMessage(delivery, taskProcessor) returnnil }
log.DEBUG.Printf("Received new message: %s", delivery)
// BackendFactory creates a new object of backends.Interface // Currently supported backends are AMQP/S and Memcache funcBackendFactory(cnf *config.Config)(backendiface.Backend, error) {
if strings.HasPrefix(cnf.ResultBackend, "amqp://") { return amqpbackend.New(cnf), nil }
if strings.HasPrefix(cnf.ResultBackend, "amqps://") { return amqpbackend.New(cnf), nil }
if strings.HasPrefix(cnf.ResultBackend, "memcache://") { parts := strings.Split(cnf.ResultBackend, "memcache://") iflen(parts) != 2 { returnnil, fmt.Errorf( "Memcache result backend connection string should be in format memcache://server1:port,server2:port, instead got %s", cnf.ResultBackend, ) } servers := strings.Split(parts[1], ",") return memcachebackend.New(cnf, servers), nil }
if strings.HasPrefix(cnf.ResultBackend, "mongodb://") || strings.HasPrefix(cnf.ResultBackend, "mongodb+srv://") { return mongobackend.New(cnf) }
if strings.HasPrefix(cnf.ResultBackend, "eager") { return eagerbackend.New(), nil }
if strings.HasPrefix(cnf.ResultBackend, "null") { return nullbackend.New(), nil }
if strings.HasPrefix(cnf.ResultBackend, "https://dynamodb") { return dynamobackend.New(cnf), nil }
returnnil, fmt.Errorf("Factory failed with result backend: %v", cnf.ResultBackend) }
其创建的方式和Broker类似,不做过多废话。
Redis的Backend结构
1 2 3 4 5 6 7 8 9 10 11 12 13
// Backend represents a Redis result backend type Backend struct { common.Backend host string password string db int pool *redis.Pool // If set, path to a socket file overrides hostname socketPath string redsync *redsync.Redsync redisOnce sync.Once common.RedisConnector }
// Backend - a common interface for all result backends type Backend interface { // Group related functions InitGroup(groupUUID string, taskUUIDs []string) error GroupCompleted(groupUUID string, groupTaskCount int) (bool, error) GroupTaskStates(groupUUID string, groupTaskCount int) ([]*tasks.TaskState, error) TriggerChord(groupUUID string) (bool, error)
// TaskState represents a state of a task type TaskState struct { TaskUUID string`bson:"_id"` TaskName string`bson:"task_name"` State string`bson:"state"` Results []*TaskResult `bson:"results"` Error string`bson:"error"` CreatedAt time.Time `bson:"created_at"` TTL int64`bson:"ttl,omitempty"` }ai
// Touch the state and don't wait func(asyncResult *AsyncResult)Touch()([]reflect.Value, error) { if asyncResult.backend == nil { returnnil, ErrBackendNotConfigured }
asyncResult.GetState()
// Purge state if we are using AMQP backend if asyncResult.backend.IsAMQP() && asyncResult.taskState.IsCompleted() { asyncResult.backend.PurgeState(asyncResult.taskState.TaskUUID) }
if asyncResult.taskState.IsFailure() { returnnil, errors.New(asyncResult.taskState.Error) }
if asyncResult.taskState.IsSuccess() { return tasks.ReflectTaskResults(asyncResult.taskState.Results) }
returnnil, nil }
// GetState returns latest task state func(asyncResult *AsyncResult)GetState() *tasks.TaskState { if asyncResult.taskState.IsCompleted() { return asyncResult.taskState }
// NewGroup creates a new group of tasks to be processed in parallel funcNewGroup(signatures ...*Signature)(*Group, error) { // Generate a group UUID groupUUID := uuid.New().String() groupID := fmt.Sprintf("group_%v", groupUUID)
// Auto generate task UUIDs if needed, group tasks by common group UUID for _, signature := range signatures { if signature.UUID == "" { signatureID := uuid.New().String() signature.UUID = fmt.Sprintf("task_%v", signatureID) } signature.GroupUUID = groupID signature.GroupTaskCount = len(signatures) }
group 结构其实就是维护了多个Signature,并形成一个UUID作为标识。我们想要并发异步执行多个互不影响的任务就可以使用这个结构来进行任务编排,类似于一个WaitGroup。形成Group结构后使用 Sever.SendGroup 来进行触发。这里需要注意的是如何定义该Group的成功与失败,以及函数执行结果如何获取。
// SendGroupWithContext will inject the trace context in all the signature headers before publishing it func(server *Server)SendGroupWithContext(ctx context.Context, group *tasks.Group, sendConcurrency int)([]*result.AsyncResult, error) { span, _ := opentracing.StartSpanFromContext(ctx, "SendGroup", tracing.ProducerOption(), tracing.MachineryTag, tracing.WorkflowGroupTag) defer span.Finish()
var wg sync.WaitGroup wg.Add(len(group.Tasks)) errorsChan := make(chan error, len(group.Tasks)*2)
// Init group server.backend.InitGroup(group.GroupUUID, group.GetUUIDs())
// Init the tasks Pending state first for _, signature := range group.Tasks { if err := server.backend.SetStatePending(signature); err != nil { errorsChan <- err continue } }
pool := make(chanstruct{}, sendConcurrency) gofunc() { for i := 0; i < sendConcurrency; i++ { pool <- struct{}{} } }()
for i, signature := range group.Tasks {
if sendConcurrency > 0 { <-pool }
gofunc(s *tasks.Signature, index int) { defer wg.Done()
// GroupMeta stores useful metadata about tasks within the same group // E.g. UUIDs of all tasks which are used in order to check if all tasks // completed successfully or not and thus whether to trigger chord callback type GroupMeta struct { GroupUUID string`bson:"_id"` TaskUUIDs []string`bson:"task_uuids"` ChordTriggered bool`bson:"chord_triggered"` Lock bool`bson:"lock"` CreatedAt time.Time `bson:"created_at"` TTL int64`bson:"ttl,omitempty"` }
// InitGroup creates and saves a group meta data object func(b *Backend)InitGroup(groupUUID string, taskUUIDs []string)error { groupMeta := &tasks.GroupMeta{ GroupUUID: groupUUID, TaskUUIDs: taskUUIDs, CreatedAt: time.Now().UTC(), }
for i, asyncResult := range asyncResults { results, err := asyncResult.Get(time.Duration(time.Millisecond * 5)) if err != nil { t.Error(err) }
iflen(results) != 1 { t.Errorf("Number of results returned = %d. Wanted %d", len(results), 1) }
intResult, ok := results[0].Interface().(int64) if !ok { t.Errorf("Could not convert %v to int64", results[0].Interface()) } actualResults[i] = intResult }
sort.Sort(ascendingInt64s(actualResults))
if !reflect.DeepEqual(expectedResults, actualResults) { t.Errorf( "expected results = %v, actual results = %v", expectedResults, actualResults, ) } }
当然SendGroup也是可以进行并发控制的如果你一次塞入的任务过多你可以将并发量调大。
Chord
Chord 结构
1 2 3 4 5 6
// Chord adds an optional callback to the group to be executed // after all tasks in the group finished type Chord struct { Group *Group Callback *Signature }
// NewChord creates a new chord (a group of tasks with a single callback // to be executed after all tasks in the group has completed) funcNewChord(group *Group, callback *Signature)(*Chord, error) { if callback.UUID == "" { // Generate a UUID for the chord callback callbackUUID := uuid.New().String() callback.UUID = fmt.Sprintf("chord_%v", callbackUUID) }
// Add a chord callback to all tasks for _, signature := range group.Tasks { signature.ChordCallback = callback }
// SendChordWithContext will inject the trace context in all the signature headers before publishing it func(server *Server)SendChordWithContext(ctx context.Context, chord *tasks.Chord, sendConcurrency int)(*result.ChordAsyncResult, error) { span, _ := opentracing.StartSpanFromContext(ctx, "SendChord", tracing.ProducerOption(), tracing.MachineryTag, tracing.WorkflowChordTag) defer span.Finish()
// taskSucceeded updates the task state and triggers success callbacks or a // chord callback if this was the last task of a group with a chord callback func(worker *Worker)taskSucceeded(signature *tasks.Signature, taskResults []*tasks.TaskResult)error { // Update task state to SUCCESS if err := worker.server.GetBackend().SetStateSuccess(signature, taskResults); err != nil { return fmt.Errorf("Set state to 'success' for task %s returned error: %s", signature.UUID, err) }
// Log human readable results of the processed task var debugResults = "[]" results, err := tasks.ReflectTaskResults(taskResults) if err != nil { log.WARNING.Print(err) } else { debugResults = tasks.HumanReadableResults(results) } log.DEBUG.Printf("Processed task %s. Results = %s", signature.UUID, debugResults)
// Trigger success callbacks
for _, successTask := range signature.OnSuccess { if signature.Immutable == false { // Pass results of the task to success callbacks for _, taskResult := range taskResults { successTask.Args = append(successTask.Args, tasks.Arg{ Type: taskResult.Type, Value: taskResult.Value, }) } }
worker.server.SendTask(successTask) }
// If the task was not part of a group, just return if signature.GroupUUID == "" { returnnil }
// There is no chord callback, just return if signature.ChordCallback == nil { returnnil }
// Check if all task in the group has completed groupCompleted, err := worker.server.GetBackend().GroupCompleted( signature.GroupUUID, signature.GroupTaskCount, ) if err != nil { return fmt.Errorf("Completed check for group %s returned error: %s", signature.GroupUUID, err) }
// If the group has not yet completed, just return if !groupCompleted { returnnil }
// Defer purging of group meta queue if we are using AMQP backend if worker.hasAMQPBackend() { defer worker.server.GetBackend().PurgeGroupMeta(signature.GroupUUID) }
// Trigger chord callback shouldTrigger, err := worker.server.GetBackend().TriggerChord(signature.GroupUUID) if err != nil { return fmt.Errorf("Triggering chord for group %s returned error: %s", signature.GroupUUID, err) }
// Chord has already been triggered if !shouldTrigger { returnnil }
// Get task states taskStates, err := worker.server.GetBackend().GroupTaskStates( signature.GroupUUID, signature.GroupTaskCount, ) if err != nil { log.ERROR.Printf( "Failed to get tasks states for group:[%s]. Task count:[%d]. The chord may not be triggered. Error:[%s]", signature.GroupUUID, signature.GroupTaskCount, err, ) returnnil }
// Append group tasks' return values to chord task if it's not immutable for _, taskState := range taskStates { if !taskState.IsSuccess() { returnnil }
if signature.ChordCallback.Immutable == false { // Pass results of the task to the chord callback for _, taskResult := range taskState.Results { signature.ChordCallback.Args = append(signature.ChordCallback.Args, tasks.Arg{ Type: taskResult.Type, Value: taskResult.Value, }) } } }
// Send the chord task _, err = worker.server.SendTask(signature.ChordCallback) if err != nil { return err }
// GroupCompleted returns true if all tasks in a group finished func(b *Backend)GroupCompleted(groupUUID string, groupTaskCount int)(bool, error) { conn := b.open() defer conn.Close()
// ChordAsyncResult represents a result of a chord type ChordAsyncResult struct { groupAsyncResults []*AsyncResult chordAsyncResult *AsyncResult backend iface.Backend }
// Get returns result of a chord (synchronous blocking call) func(chordAsyncResult *ChordAsyncResult)Get(sleepDuration time.Duration)([]reflect.Value, error) { if chordAsyncResult.backend == nil { returnnil, ErrBackendNotConfigured }
var err error for _, asyncResult := range chordAsyncResult.groupAsyncResults { _, err = asyncResult.Get(sleepDuration) if err != nil { returnnil, err } }
// NewChain creates a new chain of tasks to be processed one by one, passing // results unless task signatures are set to be immutable funcNewChain(signatures ...*Signature)(*Chain, error) { // Auto generate task UUIDs if needed for _, signature := range signatures { if signature.UUID == "" { signatureID := uuid.New().String() signature.UUID = fmt.Sprintf("task_%v", signatureID) } }
for i := len(signatures) - 1; i > 0; i-- { if i > 0 { signatures[i-1].OnSuccess = []*Signature{signatures[i]} } }
// SendChainWithContext will inject the trace context in all the signature headers before publishing it func(server *Server)SendChainWithContext(ctx context.Context, chain *tasks.Chain)(*result.ChainAsyncResult, error) { span, _ := opentracing.StartSpanFromContext(ctx, "SendChain", tracing.ProducerOption(), tracing.MachineryTag, tracing.WorkflowChainTag) defer span.Finish()
tracing.AnnotateSpanWithChainInfo(span, chain)
return server.SendChain(chain) }
// SendChain triggers a chain of tasks func(server *Server)SendChain(chain *tasks.Chain)(*result.ChainAsyncResult, error) { _, err := server.SendTask(chain.Tasks[0]) if err != nil { returnnil, err }
// Get returns results of a chain of tasks (synchronous blocking call) func(chainAsyncResult *ChainAsyncResult)Get(sleepDuration time.Duration)([]reflect.Value, error) { if chainAsyncResult.backend == nil { returnnil, ErrBackendNotConfigured }
var ( results []reflect.Value err error )
for _, asyncResult := range chainAsyncResult.asyncResults { results, err = asyncResult.Get(sleepDuration) if err != nil { returnnil, err } }
return results, err }
// GetWithTimeout returns results of a chain of tasks with timeout (synchronous blocking call) func(chainAsyncResult *ChainAsyncResult)GetWithTimeout(timeoutDuration, sleepDuration time.Duration)([]reflect.Value, error) { if chainAsyncResult.backend == nil { returnnil, ErrBackendNotConfigured }
// RegisterPeriodicGroup register a periodic group which will be triggered periodically func(server *Server)RegisterPeriodicGroup(spec, name string, sendConcurrency int, signatures ...*tasks.Signature)error { //check spec schedule, err := cron.ParseStandard(spec) if err != nil { return err }
f := func() { // new group group, _ := tasks.NewGroup(tasks.CopySignatures(signatures...)...)