高性能 Golang 并发包 – ant
接触了很多比较热的并发包和小工具,比如之前我写到的Tunny,Machinery等等,我觉得设计的最好的还是 ant,当然Tunny更轻便,Machinery主打分布式并发处理各自有自身优势,但如果你要选一个单服务进行的生产消费的并发处理包,那一定是 ant。
ant 把很多性能优化都做到了很好,在高并发种容易出现的内存泄露,GC压力等问题都在设计上进行了很好的规避,让性能做到起飞。
下面我通过源码来和大家一起学习下它的一些精彩设计。
程序流程:
ant 的主体是pool结构 ,pool结构管理着worker队列,worker是执行任务的最小单位。
生产者不断提交任务给pool,pool 进行任务的调度处理。
下面是整个包工作的流程图:
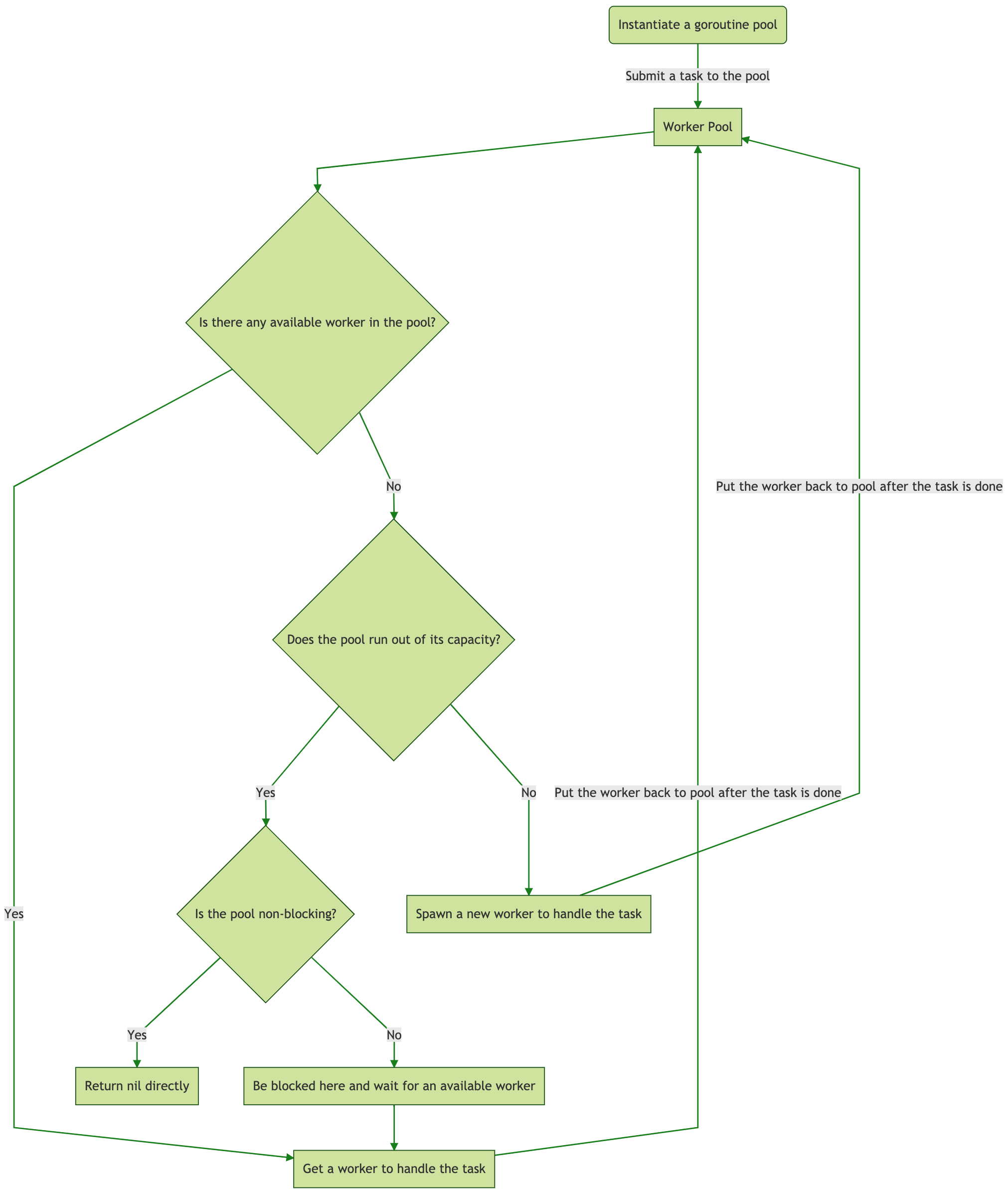
主体架构
整个包设计的主体分为三层最上层是pool 接够,中层是queue结构,底层是worker结构。
处理任务的最小单位是worker 结构,queue其实就一个worker的队列,负责worker的调度和清理等工作,pool是最上层的结构也就是我们接触到的使用结构,pool主要负责并发数量控制,task发送,worker获取放回等工作。
下面我们通过源码从pool,queue,worker这三个方面逐步进行解析,来学习作者的并发处理方式和设计理念。
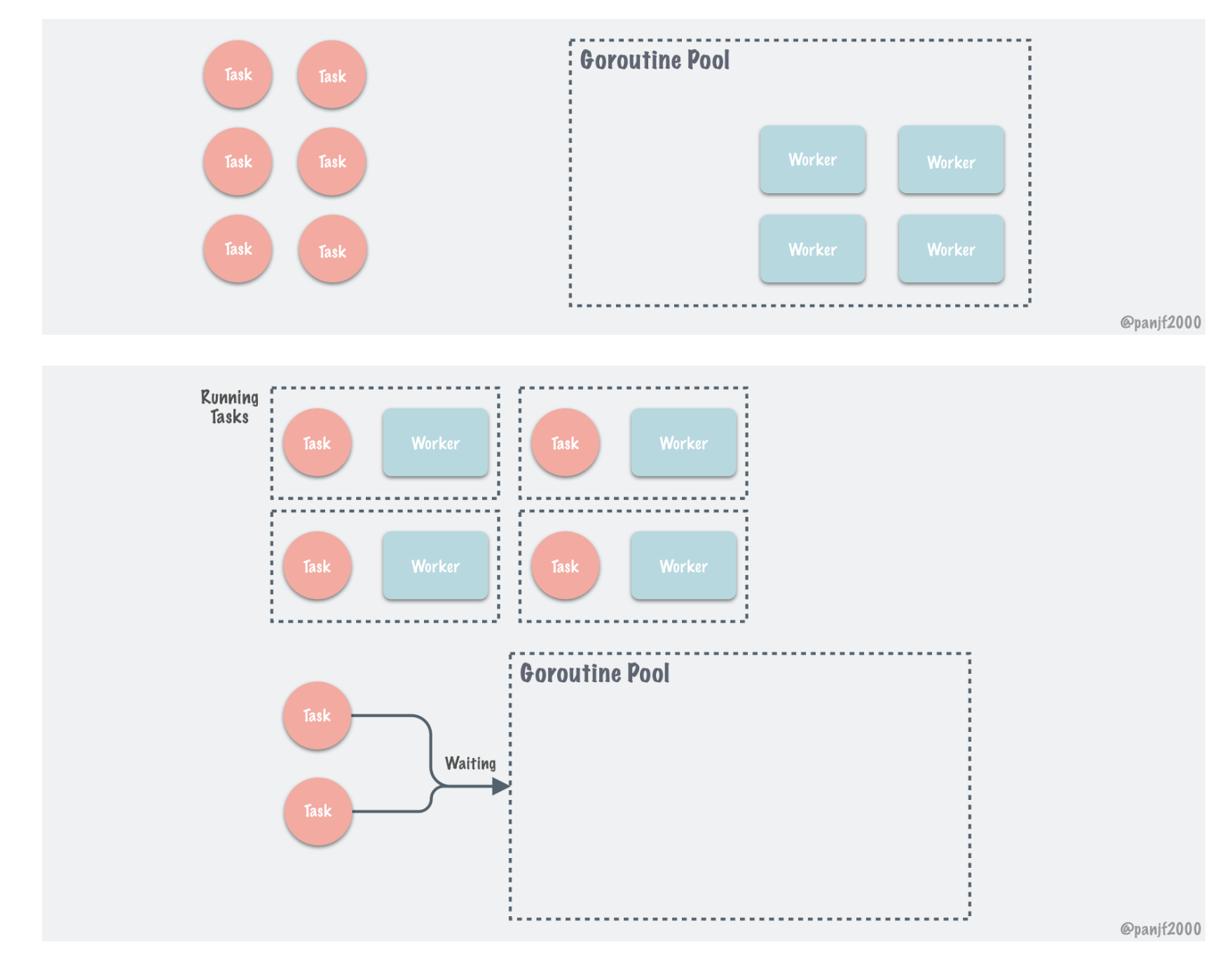
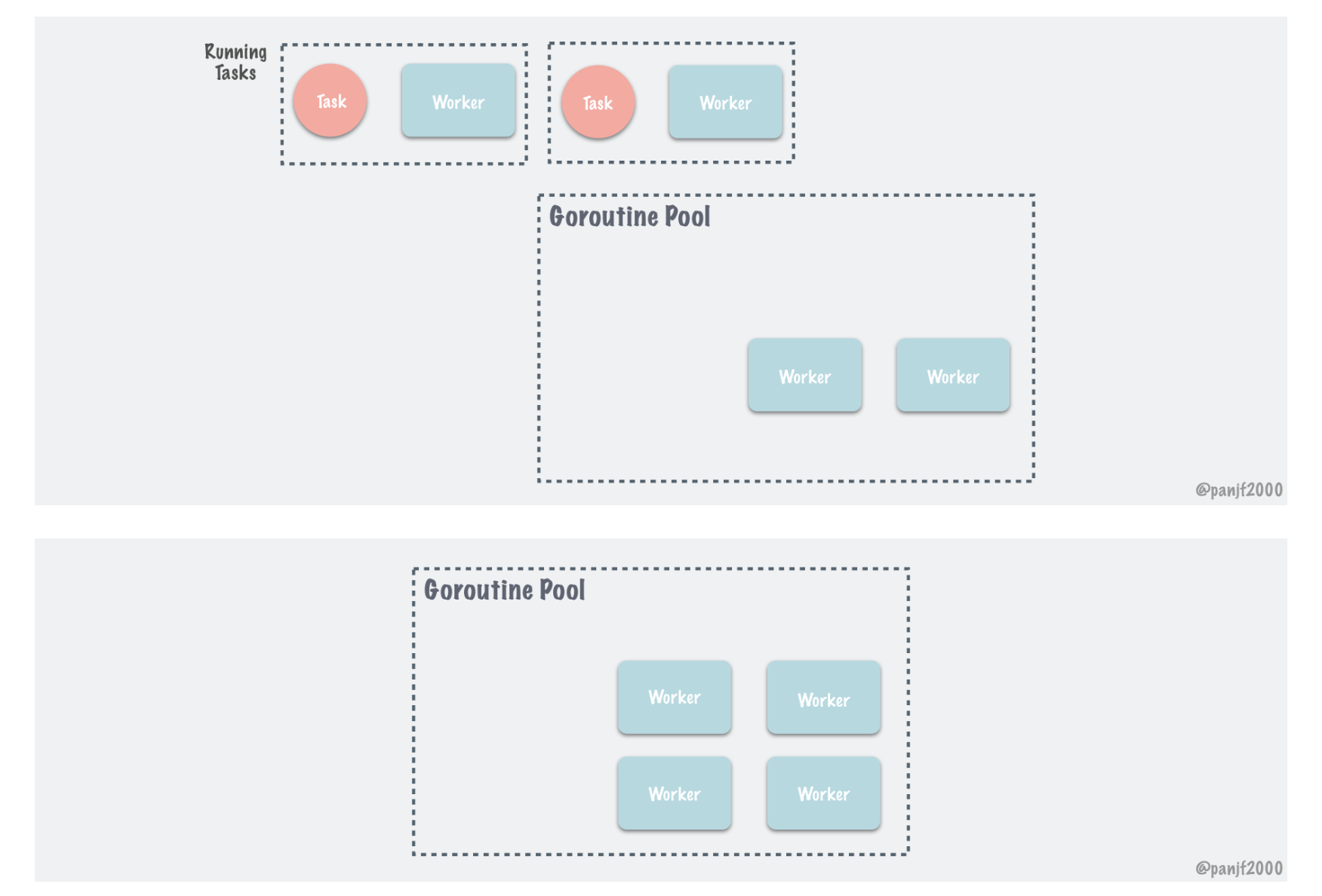
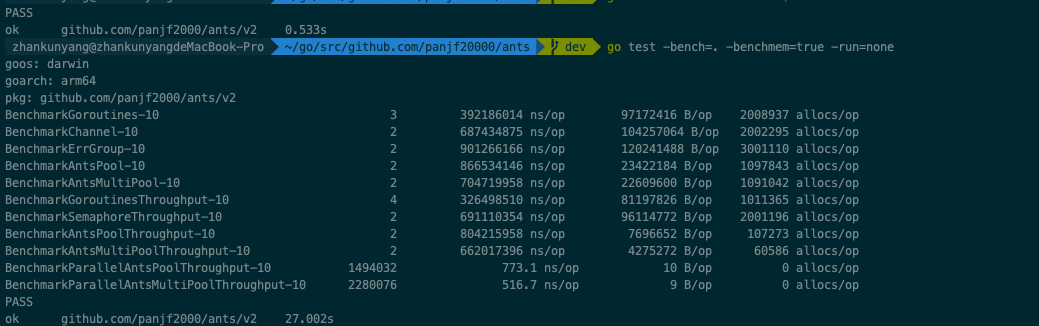
性能对比
作者在README上贴上了性能和普通起并发以及使用channel,errgroup 包控制并发,进行比较性能提升很大,我自己跑了一遍他的test方法,确实是这样的,尤其在内存使用上,ant包的优势显而易见,接近5倍的内存节省。
源码解析:
pool
作者设计了两种处理任务的worker,分别是worker 和 workerfunc 通过这两种不同的worker衍生出了两种pool,分别是pool和poolfunc。其实两个pool的设计是相似的,这里我们只看pool的源码就好。
pool 结构体
1 | // Pool accepts the tasks from client, it limits the total of goroutines to a given number by recycling goroutines. |
我们来一个个字段看
capacity:这个字段是比较重要的,pool的容量,即并发最大数量,你在新建pool时可以指定,只要并发量达到这个值,生产方就要等待,直到有worker 释放出来为止。
running:这个字段统计了当前正在执行工作的worker数量,在worker任务开始时加一,结束释放时减一。
lock:这个lock对workerqueue进行保护,当使用该资源时先要上锁。
workers:这个就是我们说的中层queue结构,也就时worker队列。
state:这个统计了当前pool的打开或关闭状态,这个状态值也同事影响着pool边缘程序 (清理,时间更新) 的执行。
cond:这个使用的是 sync 包的 cond 结构,这个结构可以在生产和消费两端进行唤醒操作,在 an t 中这个结构是在消费端有空闲worker释放或新建时进行单个或多个生产端的唤醒操作。
workerCache:刚刚我们说了在性能方面,ant 在内存使用上完胜了裸写和errgroup这种简单的并发控制程序,workerCache是使性能提升的主要利器,这个结构使用了sync包的pool结构,主要在worker 过期时不直接干掉,而是缓存起来在下次新建时取出,这个结构不仅减少内存使用而且减少了大量的gc处理,在长时间运行程序时降低cpu使用波动和极值。
waiting:该字段统计了在生产端,由于无法获取空闲worker而悬停的生产者的数量,这个所谓的悬停在后面讲pool 的retrieveWorker方法时会说,这点很重要,这意味着你如果容量限制的比较小,生产者是会被卡住的。
purgeDone:这个字段是 pool 清理过期worker的程序关闭与否的一个状态,如果该程序退出那么purgeDone 为1。
stopPurge:用来停止清理过期worker的执行程序。
ticktockDone: 和purgeDone 类似,标记pool的更新最新时间程序退出与否。
stopTicktock:同理这个也是用来停止更新最新时间的的控制器。
now: 最新时间戳。
options: 一些可配置选项。
我们来看下option的结构的一些字段:
1 | // Options contains all options which will be applied when instantiating an ants pool. |
- ExpiryDuration: 这个字段是清理过期worker的时间段,每过一个单位时间,就会把这个时间内过期的worker清理掉,如何判断worker过期,这个后面会说到。
- PreAlloc:这个字段是确认是否提前为queue 分配容量,queue前面也说了就是一个worker的操作队列,这个字段设置为true即为操作队列提前做了一个固定容量,这个的好处是在提前知道有高数量并发并且是去执行时间较长的任务时,可以在任务增加时减少扩容的性能消耗。注意:这个字段设置为true那么之后pool的动态扩容方法将不再支持。
- MaxBlockingTasks:这个字段决定你的最大等待生产者等待数量,这个字段非常重要,如果设置成 0 则生产者的等待数量不受到限制,如果大于0,则一旦生产者的等待数大于这个值那么,这个任务执行将直接被抛弃,如果对于数据要求很高建议不要设置这个值。
- Nonblocking:这个字段如果为true,那么将不允许生产任务的悬停,如果在提交任务后没有容量,那么这个任务不做悬停,直接抛弃。最好不要设置为true,除非你的任务不重要,你更重视任务不要堆积,而不是任务是否执行那么设置为true时非常棒的选择。
- PanicHandler:这个就是在出现panic时外包一层自己的处理,比如打日志到文件。
- Logger:日志接口,不自定义就是defaultlog。你可以看下他的默认log。
- DisablePurge:这个字段如果为true那么将不会运行过期任务清理的协程。worker 降永远存留于使用队列中,这样的好处是减少了一些cpu使用,但失去了ant的内存优化目的。
pool 方法
我们只做主要方法的介绍
NewPool
新建池子
1 | // NewPool generates an instance of ants pool. |
这个方法就是按照你的容量和一些选项来建立池子,
lock: syncx.NewSpinLock(),这个spinlock是一个自旋锁,这个锁使用在多个地方,主要是queue的原子化操作,避免数据错乱,还有就是cond包在等待时的加入等待队列的等待队列资源的原子化操作。
workerCache:
1 | p.workerCache.New = func() interface{} { |
这个workerCache字段刚刚提过是sync包中的pool结构,这个结构维持一个结构体队列缓存,在结构体使用完或是清理后可以放入这个队列,再次使用时直接从缓存队列获取,这个workerChanCap参数是缓存队列的容量,这个参数是作者实现的一个方法如果CPU核心为1则使用无缓冲管道,大于1则使用缓冲1管道。单核环境下使用无缓冲管道可以让协程阻塞休眠让出宝贵的CPU减少其他协程的延迟。多核就可以使用有缓存的管道,减少生产者阻塞。
在pool 创建完毕后启动两个协程p.goPurge(),p.goTicktock()分别用来清理过期worker和pool中当前时间戳更新。
接下来看看这个两个协程任务:
goPurge
1 | func (p *Pool) goPurge() { |
运行定期清理任务,首先要看你是否定义了需要定时清理的选项 p.options.DisablePurge,然后创建ctx上下文用于结束通知。
最后运行核心方法:purgeStaleWorkers
1 | // purgeStaleWorkers clears stale workers periodically, it runs in an individual goroutine, as a scavenger. |
这个方法在每个ExpiryDuration时段运行一次,运行的核心方法为 p.workers.refresh(p.options.ExpiryDuration) 这个一会儿在worker介绍中会讲,主要就是把所有的过期worker清理掉。最后进行生产端广播,这个广播是为了解决在结束worker后突然进入的生产端任务提交。
goTicktock
1 | func (p *Pool) goTicktock() { |
这个方法和清理的逻辑一样,核心逻辑,在 p.ticktock(ctx):
1 | // ticktock is a goroutine that updates the current time in the pool regularly. |
这个方法就是定时更新当前时间戳。
Submit
任务提交
1 | // Submit submits a task to this pool. |
任务提交方法就是生产者调用worker进行数据消费的连接代码,生产者使用submit方法来提交一个需要处理的任务,pool在接受到任务后调度一个worker,将任务注入worker中。
这个获取worker的核心逻辑在p.retrieveWorker()这个函数下,这个函数是我任务最重要的一个函数,作者做了很精妙的设计,我们详细看下:
retrieveWorker
1 | // retrieveWorker returns an available worker to run the tasks. |
先创建一个获取spanworker的方法,这个方法是用来新建一个 worker,这个workerCache上面说过了就不多赘述,使用get方法从缓存队列中获取worker结构,如果缓存队列中没有就新建。获取worker结构后run()启动worker的消费协程。
创建生成方法后,上锁先尝试从已有的活跃worker队列中获取worker,也就是p.workers.detach(),这个detach方法在后面讲 worker 结构的时候会说到,就是从现有活跃worker队列中取出一个。
如果有反出,如果没有活跃的 worker 那么判断容量是否上限,如果没有上限,就进行worker生成返回。如果达到上限,先判断是不是不允许有等待生产者,如果不允许直接返回不做任务处理。如果可以有生产者等待那么看有没有设置最大等待生产者数,如果有就判断是否等待数超限制,若超限制直接返回不做任务处理。
没有超出限制就进行waiting数加一,使用 p.cond.Wait() 进行悬停等待唤醒,一旦被唤醒就继续去detach() worker,若仍然没有取到就继续判断等待数等指标满足条件继续等待,不满足直接返回不做任务处理。
注意:在生产者提交任务的过程中是会悬停等待的,这个过程中如果你不断的提交任务那么有可能产生阻塞。好的方法是多建立几个pool分片去处理任务,或者你的并发量不会失控的情况下不设置容量上限,就是capacity字段置为-1。
revertWorker
1 | // revertWorker puts a worker back into free pool, recycling the goroutines. |
这个方法用来回收执行完任务的worker。如果使用中的worker已经大于容量或是pool已经关闭则直接广播唤醒生产者,不做回收。
如果满足回收条件则更新使用时间为最新回收到活跃 worker 队列中。
ReleaseTimeout
1 | // ReleaseTimeout is like Release but with a timeout, it waits all workers to exit before timing out. |
释放池子,这个释放池子的方法是优雅的释放,就是先释放,然后在一段时间内检查是否成功释放,成功释放返回nil,不成功返回err。
1 | // Release closes this pool and releases the worker queue. |
这个释放的方法非常简单就是将池子状态置为1,在清理和更新时间的两个定时协程中都会检查这个状态查到为1即退出,在生产者中也会检查这个,可以看到release方法最后是广播方法,用来唤醒所有的生产者,在悬停过程中被唤醒生产者先检查这个状态,为1直接解锁退出。p.workers.reset()就是释放worker队列,这个在queue结构中会说。
Tune
1 | // Tune changes the capacity of this pool, note that it is noneffective to the infinite or pre-allocation pool. |
这个方法来进行池子扩容,如果提前设置了队列容量:p.options.PreAlloc=true或者容量无限大:capacity == -1 或者扩容的size等于容量或为负数就不可扩容,其他情况为可以扩容,则改变容量,唤醒生产者。
这个方法可以用来做你自己的扩容逻辑,比如你可以不断的检查池子的的waiting数量然后到达一个极值就进行对应倍数的扩容。
Queue
接下来我们来看工作队列结构。
ant设计了两种工作队列,一种是固定长度的循环数组结构队列(loopQueue),这种队列在你选择 p.options.PreAlloc 为true时建立,这中队列一开始就定义死了数组长度,如果你的并发数是固定且任务执行时间很长建议用这种队列减少扩容成本,但大部分情况中我们都适用第二种queue:workerStack,不固定长度但可以指定容量。
我们只看这个workerStack:
workerStack结构体
1 | type workerStack struct { |
workerStack的结构非常简单,两个worke队列,其中item是活跃worker队列,expiry是过期worker队列。两个都是worker接口的数组结构。
workerStack方法
insert
1 | func (wq *workerStack) insert(w worker) error { |
加入活跃对列一个worker
detach
1 | func (wq *workerStack) detach() worker { |
获取一个worker,如果队列有元素那么就取活跃队列最后一个worker。
refresh
1 | func (wq *workerStack) refresh(duration time.Duration) []worker { |
1 | func (wq *workerStack) binarySearch(l, r int, expiryTime time.Time) int { |
就是用二分查找的方式找到这个expiryTime对应下标或是最近一个大于他的worker的下标然后,把下标到队列尾部的数据全放入expiry然后去掉在item中的这组数据
reset
1 | func (wq *workerStack) reset() { |
reset 方法将所有的活跃队列都结束掉然后队列清零。这个就是在pool的Release方法中调用的。
最后我们还剩最底层的任务执行结构:worker
Worker
worker 的结构ant也设计了两种,并且封装了接口,你可以自己实现一个worker。
worker的两种结构分别是goWorker和goWorkerfunc,goWorker 是传入一个方法,goWorkerfunc是把方法注册在pool中然后传入参数。两者的设计差不多,你可以根据你的需要来选择,当然也可以自截实现worker,这里只介绍goWorker。
使用goWorker的时候要注意下闭包参数的堆栈问题
goWorker 结构体
1 | // goWorker is the actual executor who runs the tasks, |
- Pool: 就是上面的pool结构每次生成一个worker都把当前的pool结构指针注入进去。用来进行worker的Runing状态记录,有闲置worker时进行唤醒通知。
- task:数据或是函数的传入提交。
- lastUsed: 最新的时间戳。
goWorker 方法
run
1 | // run starts a goroutine to repeat the process |
其实worker的核心方法就一个run,启动worker对注入任务进行消费,worker run起后会先对pool 中的 running 数量加一,然后会启动一个 go 程,在 go 程中,不断的去监听task 管道,得到任务就执行。
在执行结束后,紧接着会调用w.pool.revertWorker来将停止的worker放回活跃worker队列,其实活跃worker队列其实就一个worker chan队列,如果任务到来时会从队列中获取这个worker 进行任务注入,也就是将task放入worker chan中。
在获取到任务为 nil 时那么将会中断协程,下面的finish方法就是利用这个设计去中断一个worker。
worker 中断之后会进入defer的方法中,这个方法会将 runing 减一然后把worker 回收到workerCache中,这个workerCache是之前讲的pool 中的syncpool结构,回收后worker将会形成被引用的状态从而不进入GC被释放,减少内存使用同时减少GC压力,这个设计非常好,大家以后可以借鉴。
最后处理Panic,以及 w.pool.cond.Signal()通知等待生产者有容量空闲。
inputFunc
1 | func (w *goWorker) inputFunc(fn func()) { |
用于将任务消费方法注入worker
finish
1 | func (w *goWorker) finish() { |
该方法用来结束当前的worker协程
精彩设计
我们结合之前的pool,queue,worker结构来看下作者的比较好的设计。
使用sync.pool结构来节省内存,以及减少GC压力。
定期清理闲置时间过长worker,这个设计很好的降低了在低任务量时间内的工作协程数量,在很多并发池的设计中其实不会考虑低任务量时的性能占用问题,但是ant就很好的将这个问题给解决了。
生产者在容量超限制时进行悬停等待然后使用 sync.cond 唤醒重试。这样做的好处是可以在并发压力大的时候进行任务丢弃避免任务阻塞。每个悬停的生产者都会记录一个waiting数,你可以配置在waiting等待数量多少时进行任务丢弃,多数池子不会考虑这些如果并发过量就直接管道阻塞等待,这样很容易出现任务堆积,在不太重视每个任务都执行的海量数据流处理中这个设计是很好的,这个设计最好的使用方式就是并发生产进行数据发送,比如同一个数据需要不同的处理,就可以并发生产者来进行任务发送,在并发发送的过程中如果过多的任务等待可以进行适量的任务抛弃。
可以根据waiting 数量动态扩容,你也可以在 waiting 数到一定程度时使用Tune方法进行扩容,waiting减少之后进行容量还原,当然事先算好可以支撑并发量是最好的。




