想要写好Go并发不得不掌握的数据结构
Map
哈希表(Hash Table)这个数据结构,我们已经非常熟悉了。它实现的就是 key-value 之间的映射关系,主要提供的方法包括 Add、Lookup、Delete 等。因为这种数据结构是一个基础的数据结构,每个 key 都会有一个唯一的索引值,通过索引可以很快地找到对应的值,所以使用哈希表进行数据的插入和读取都是很快的。Go 语言本身就内建了这样一个数据结构,也就是 map 数据类型。
map 的基本使用方法
1 | map[K]V |
其中,key 类型的 K 必须是可比较的(comparable),也就是可以通过 == 和 != 操作符进行比较;value 的值和类型无所谓,可以是任意的类型,或者为 nil。
在 Go 语言中,bool、整数、浮点数、复数、字符串、指针、Channel、接口都是可比较的,包含可比较元素的 struct 和数组,这俩也是可比较的,而 slice、map、函数值都是不可比较的。
那么,上面这些可比较的数据类型都可以作为 map 的 key 吗?显然不是。通常情况下,我们会选择内建的基本类型,比如整数、字符串做 key 的类型,因为这样最方便。
如果要使用 struct 作为 key,我们要保证 struct 对象在逻辑上是不可变的,这样才会保证 map 的逻辑没有问题。
在 Go 中,map[key]函数返回结果可以是一个值,也可以是两个值,这是容易让人迷惑的地方。原因在于,如果获取一个不存在的 key 对应的值时,会返回零值。为了区分真正的零值和 key 不存在这两种情况,可以根据第二个返回值来区分
map 是无序的,所以当遍历一个 map 对象的时候,迭代的元素的顺序是不确定的,无法保证两次遍历的顺序是一样的,也不能保证和插入的顺序一致。那怎么办呢?如果我们想要按照 key 的顺序获取 map 的值,需要先取出所有的 key 进行排序,然后按照这个排序的 key 依次获取对应的值。而如果我们想要保证元素有序,比如按照元素插入的顺序进行遍历,可以使用辅助的数据结构,比如orderedmap,来记录插入顺序。
使用 map 的 2 种常见错误
常见错误一:未初始
和 slice 或者 Mutex、RWmutex 等 struct 类型不同,map 对象必须在使用之前初始化。如果不初始化就直接赋值的话,会出现 panic 异常,比如下面的例子,m 实例还没有初始化就直接进行操作会导致 panic(第 3 行):
1 | func main() { |
解决办法就是在第 2 行初始化这个实例(m := make(map[int]int))。
从一个 nil 的 map 对象中获取值不会 panic,而是会得到零值,所以下面的代码不会报错:
1 | func main() { |
这个例子很简单,我们可以意识到 map 的初始化问题。但有时候 map 作为一个 struct 字段的时候,就很容易忘记初始化了。
所以,关于初始化这一点,我再强调一下,目前还没有工具可以检查,我们只能记住“别忘记初始化”这一条规则。
常见错误二:并发读写
对于 map 类型,另一个很容易犯的错误就是并发访问问题。这个易错点,相当令人讨厌,如果没有注意到并发问题,程序在运行的时候就有可能出现并发读写导致的 panic。
Go 内建的 map 对象不是线程(goroutine)安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致 panic。
我们一起看一个并发访问 map 实例导致 panic 的例子:
1 | func main() { |
如何实现线程安全的 map 类型?
加读写锁:扩展 map,支持并发读写比较遗憾的是,目前 Go 还没有正式发布泛型特性,我们还不能实现一个通用的支持泛型的加锁 map。
但是,将要发布的泛型方案已经可以验证测试了,离发布也不远了,也许发布之后 sync.Map 就支持泛型了。
当然了,如果没有泛型支持,我们也能解决这个问题。我们可以通过 interface{}来模拟泛型,但还是要涉及接口和具体类型的转换,比较复杂,还不如将要发布的泛型方案更直接、性能更好。这里我以一个具体的 map 类型为例,来演示利用读写锁实现线程安全的 map[int]int 类型:
1 | type RWMap struct { // 一个读写锁保护的线程安全的map |
分片加锁:更高效的并发 map
虽然使用读写锁可以提供线程安全的 map,但是在大量并发读写的情况下,锁的竞争会非常激烈。我在第 4 讲中提到过,锁是性能下降的万恶之源之一。
在并发编程中,我们的一条原则就是尽量减少锁的使用。一些单线程单进程的应用(比如 Redis 等),基本上不需要使用锁去解决并发线程访问的问题,所以可以取得很高的性能。但是对于 Go 开发的应用程序来说,并发是常用的一个特性,在这种情况下,我们能做的就是,尽量减少锁的粒度和锁的持有时间。
减少锁的粒度常用的方法就是分片(Shard),将一把锁分成几把锁,每个锁控制一个分片。Go 比较知名的分片并发 map 的实现是orcaman/concurrent-map。
它默认采用 32 个分片,GetShard 是一个关键的方法,能够根据 key 计算出分片索引。
1 | var SHARD_COUNT = 32 |
在我个人使用并发 map 的过程中,加锁和分片加锁这两种方案都比较常用,如果是追求更高的性能,显然是分片加锁更好,因为它可以降低锁的粒度,进而提高访问此 map 对象的吞吐。如果并发性能要求不是那么高的场景,简单加锁方式更简单。
Sync.Map
Go 内建的 map 类型不是线程安全的,所以 Go 1.9 中增加了一个线程安全的 map,也就是 sync.Map。但是,我们一定要记住,这个 sync.Map 并不是用来替换内建的 map 类型的,它只能被应用在一些特殊的场景里。那这些特殊的场景是啥呢?
官方的文档中指出,在以下两个场景中使用 sync.Map,会比使用 map+RWMutex 的方式,性能要好得多:
只会增长的缓存系统中,一个 key 只写入一次而被读很多次;
多个 goroutine 为不相交的键集读、写和重写键值对。
这两个场景说得都比较笼统,而且,这些场景中还包含了一些特殊的情况。所以,官方建议你针对自己的场景做性能评测,如果确实能够显著提高性能,再使用 sync.Map。这么来看,我们能用到 sync.Map 的场景确实不多。即使是 sync.Map 的作者 Bryan C. Mills,也很少使用 sync.Map,即便是在使用 sync.Map 的时候,也是需要临时查询它的 API,才能清楚记住它的功能。所以,我们可以把 sync.Map 看成一个生产环境中很少使用的同步原语。
sync.Map 的实现
- 空间换时间。通过冗余的两个数据结构(只读的 read 字段、可写的 dirty),来减少加锁对性能的影响。对只读字段(read)的操作不需要加锁。
- 优先从 read 字段读取、更新、删除,因为对 read 字段的读取不需要锁。
- 动态调整。miss 次数多了之后,将 dirty 数据提升为 read,避免总是从 dirty 中加锁读取。
- double-checking。加锁之后先还要再检查 read 字段,确定真的不存在才操作 dirty 字段。
- 延迟删除。删除一个键值只是打标记,只有在提升 dirty 字段为 read 字段的时候才清理删除的数据。
我们先看一下 map 的数据结构:
1 | type Map struct { |
如果 dirty 字段非 nil 的话,map 的 read 字段和 dirty 字段会包含相同的非 expunged 的项,所以如果通过 read 字段更改了这个项的值,从 dirty 字段中也会读取到这个项的新值,因为本来它们指向的就是同一个地址。
dirty 包含重复项目的好处就是,一旦 miss 数达到阈值需要将 dirty 提升为 read 的话,只需简单地把 dirty 设置为 read 对象即可。不好的一点就是,当创建s dirty 对象的时候,需要逐条遍历 read,把非 expunged 的项复制到 dirty 对象中。
Store 方法
我们先来看 Store 方法,它是用来设置一个键值对,或者更新一个键值对的。
1 | func (m *Map) Store(key, value interface{}) { |
可以看出,Store 既可以是新增元素,也可以是更新元素。如果运气好的话,更新的是已存在的未被删除的元素,直接更新即可,不会用到锁。
如果运气不好,需要更新(重用)删除的对象、更新还未提升的 dirty 中的对象,或者新增加元素的时候就会使用到了锁,这个时候,性能就会下降。所以从这一点来看,sync.Map 适合那些只会增长的缓存系统,可以进行更新,但是不要删除,并且不要频繁地增加新元素。
新加的元素需要放入到 dirty 中,如果 dirty 为 nil,那么需要从 read 字段中复制出来一个 dirty 对象:
1 | func (m *Map) dirtyLocked() { |
Load 方法
Load 方法用来读取一个 key 对应的值。它也是从 read 开始处理,一开始并不需要锁
1 | func (m *Map) Load(key interface{}) (value interface{}, ok bool) { |
如果幸运的话,我们从 read 中读取到了这个 key 对应的值,那么就不需要加锁了,性能会非常好。但是,如果请求的 key 不存在或者是新加的,就需要加锁从 dirty 中读取。所以,读取不存在的 key 会因为加锁而导致性能下降,读取还没有提升的新值的情况下也会因为加锁性能下降
其中,missLocked 增加 miss 的时候,如果 miss 数等于 dirty 长度,会将 dirty 提升为 read,并将 dirty 置空。
1 | func (m *Map) missLocked() { |
Delete 方法
sync.map 的第 3 个核心方法是 Delete 方法。在 Go 1.15 中欧长坤提供了一个 LoadAndDelete 的实现(go#issue 33762),所以 Delete 方法的核心改在了对 LoadAndDelete 中实现了。同样地,Delete 方法是先从 read 操作开始,原因我们已经知道了,因为不需要锁。
1 | func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) { |
如果 read 中不存在,那么就需要从 dirty 中寻找这个项目。最终,如果项目存在就删除(将它的值标记为 nil)。如果项目不为 nil 或者没有被标记为 expunged,那么还可以把它的值返回。
最后,我补充一点,sync.map 还有一些 LoadAndDelete、LoadOrStore、Range 等辅助方法,但是没有 Len 这样查询 sync.Map 的包含项目数量的方法,并且官方也不准备提供。如果你想得到 sync.Map 的项目数量的话,你可能不得不通过 Range 逐个计数。
Pool:性能提升大杀器
Go 是一个自动垃圾回收的编程语言,采用三色并发标记算法标记对象并回收。和其它没有自动垃圾回收的编程语言不同,使用 Go 语言创建对象的时候,我们没有回收 / 释放的心理负担,想用就用,想创建就创建。
但是,如果你想使用 Go 开发一个高性能的应用程序的话,就必须考虑垃圾回收给性能带来的影响,毕竟,Go 的自动垃圾回收机制还是有一个 STW(stop-the-world,程序暂停)的时间,而且,大量地创建在堆上的对象,也会影响垃圾回收标记的时间。
所以,一般我们做性能优化的时候,会采用对象池的方式,把不用的对象回收起来,避免被垃圾回收掉,这样使用的时候就不必在堆上重新创建了。
Go 标准库中提供了一个通用的 Pool 数据结构,也就是 sync.Pool,我们使用它可以创建池化的对象。
sync.Pool
sync.Pool 数据类型用来保存一组可独立访问的临时对象。请注意这里加粗的“临时”这两个字,它说明了 sync.Pool 这个数据类型的特点,也就是说,它池化的对象会在未来的某个时候被毫无预兆地移除掉。而且,如果没有别的对象引用这个被移除的对象的话,这个被移除的对象就会被垃圾回收掉。
两个知识点你需要记住:
sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象;
sync.Pool 不可在使用之后再复制使用。
sync.Pool 的使用方法
知道了 sync.Pool 这个数据类型的特点,接下来,我们来学习下它的使用方法。其实,这个数据类型不难,它只提供了三个对外的方法:New、Get 和 Put。
New
Pool struct 包含一个 New 字段,这个字段的类型是函数 func() interface{}。当调用 Pool 的 Get 方法从池中获取元素,没有更多的空闲元素可返回时,就会调用这个 New 方法来创建新的元素。如果你没有设置 New 字段,没有更多的空闲元素可返回时,Get 方法将返回 nil,表明当前没有可用的元素。
有趣的是,New 是可变的字段。这就意味着,你可以在程序运行的时候改变创建元素的方法。当然,很少有人会这么做,因为一般我们创建元素的逻辑都是一致的,要创建的也是同一类的元素,所以你在使用 Pool 的时候也没必要玩一些“花活”,在程序运行时更改 New 的值。
Get
如果调用这个方法,就会从 Pool取走一个元素,这也就意味着,这个元素会从 Pool 中移除,返回给调用者。不过,除了返回值是正常实例化的元素,Get 方法的返回值还可能会是一个 nil(Pool.New 字段没有设置,又没有空闲元素可以返回),所以你在使用的时候,可能需要判断。
Put
这个方法用于将一个元素返还给 Pool,Pool 会把这个元素保存到池中,并且可以复用。但如果 Put 一个 nil 值,Pool 就会忽略这个值。
我们看看 sync.Pool 最常用的一个场景:buffer 池(缓冲池)。
因为 byte slice 是经常被创建销毁的一类对象,使用 buffer 池可以缓存已经创建的 byte slice,比如,著名的静态网站生成工具 Hugo 中,就包含这样的实现bufpool,你可以看一下下面这段代码:
1 | var buffers = sync.Pool{ |
除了 Hugo,这段 buffer 池的代码非常常用。很可能你在阅读其它项目的代码的时候就碰到过,或者是你自己实现 buffer 池的时候也会这么去实现,但是请你注意了,这段代码是有问题的,你一定不要将上面的代码应用到实际的产品中。它可能会有内存泄漏的问题
实现原理
当前,sync.Pool 的数据结构如下图所示:
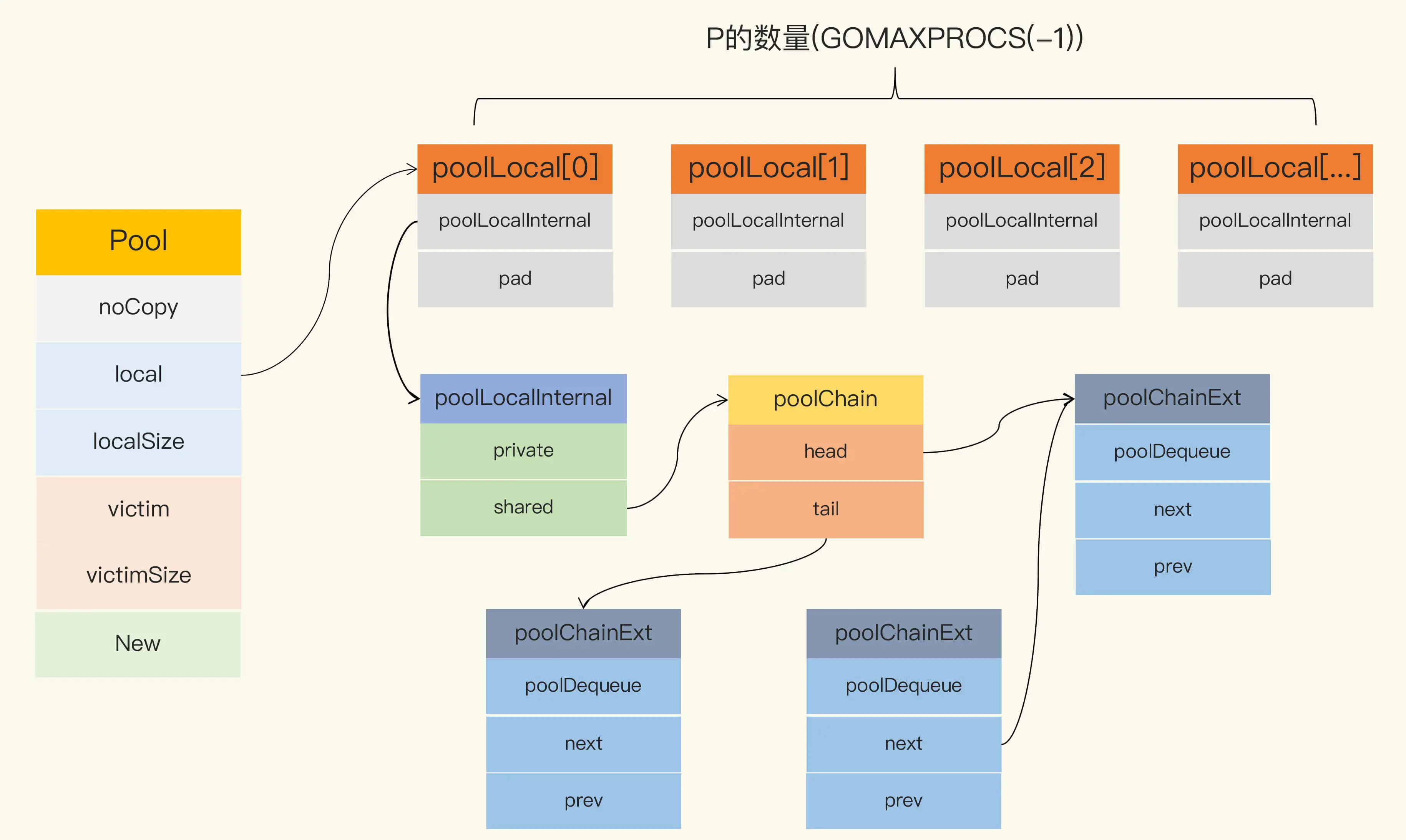
Pool 最重要的两个字段是 local 和 victim,因为它们两个主要用来存储空闲的元素。弄清楚这两个字段的处理逻辑,你就能完全掌握 sync.Pool 的实现了。下面我们来看看这两个字段的关系。
每次垃圾回收的时候,Pool 会把 victim 中的对象移除,然后把 local 的数据给 victim,这样的话,local 就会被清空,而 victim 就像一个垃圾分拣站,里面的东西可能会被当做垃圾丢弃了,但是里面有用的东西也可能被捡回来重新使用。
victim 中的元素如果被 Get 取走,那么这个元素就很幸运,因为它又“活”过来了。但是,如果这个时候 Get 的并发不是很大,元素没有被 Get 取走,那么就会被移除掉,因为没有别人引用它的话,就会被垃圾回收掉。
下面的代码是垃圾回收时 sync.Pool 的处理逻辑:
1 | func poolCleanup() { |
在这段代码中,你需要关注一下 local 字段,因为所有当前主要的空闲可用的元素都存放在 local 字段中,请求元素时也是优先从 local 字段中查找可用的元素。local 字段包含一个 poolLocalInternal 字段,并提供 CPU 缓存对齐,从而避免 false sharing。
(cpu分层读取,L1, L2, L3, 内存。当读取某一个值x做读写操作时,并不是只读取一个值,而是按块来读取(因为cpu读取,很可能会用到相邻的数据,比如把y也一起读取进去了),此时如果另一个cpu操作y,就会出现伪共享问题。解决方式:在x, y插入一些无用的内存,将y排出当前的缓存行即可。)
而 poolLocalInternal 也包含两个字段:private 和 shared。
private,代表一个缓存的元素,而且只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,所以不会有并发的问题。
shared,可以由任意的 P 访问,但是只有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相当于只有一个本地的 P 作为生产者(Producer),多个 P 作为消费者(Consumer),它是使用一个 local-free 的 queue 列表实现的。
Get
1 | func (p *Pool) Get() interface{} { |
首先,从本地的 private 字段中获取可用元素,因为没有锁,获取元素的过程会非常快,如果没有获取到,就尝试从本地的 shared 获取一个,如果还没有,会使用 getSlow 方法去其它的 shared 中“偷”一个。最后,如果没有获取到,就尝试使用 New 函数创建一个新的。
这里的重点是 getSlow 方法,我们来分析下。看名字也就知道了,它的耗时可能比较长。它首先要遍历所有的 local,尝试从它们的 shared 弹出一个元素。如果还没找到一个,那么,就开始对 victim 下手了。
在 vintim 中查询可用元素的逻辑还是一样的,先从对应的 victim 的 private 查找,如果查不到,就再从其它 victim 的 shared 中查找。
下面的代码是 getSlow 方法的主要逻辑:
1 | func (p *Pool) getSlow(pid int) interface{} { |
这里我没列出 pin 代码的实现,你只需要知道,pin 方法会将此 goroutine 固定在当前的 P 上,避免查找元素期间被其它的 P 执行。固定的好处就是查找元素期间直接得到跟这个 P 相关的 local。有一点需要注意的是,pin 方法在执行的时候,如果跟这个 P 相关的 local 还没有创建,或者运行时 P 的数量被修改了的话,就会新创建 local。
Put 方法
1 | func (p *Pool) Put(x interface{}) { |
Put 的逻辑相对简单,优先设置本地 private,如果 private 字段已经有值了,那么就把此元素 push 到本地队列中。
sync.Pool 的坑
到这里,我们就掌握了 sync.Pool 的使用方法和实现原理,接下来,我要再和你聊聊容易踩的两个坑,分别是内存泄漏和内存浪费。
内存泄漏
可以使用 sync.Pool 做 buffer 池,但是,如果用刚刚的那种方式做 buffer 池的话,可能会有内存泄漏的风险。为啥这么说呢?我们来分析一下。
取出来的 bytes.Buffer 在使用的时候,我们可以往这个元素中增加大量的 byte 数据,这会导致底层的 byte slice 的容量可能会变得很大。这个时候,即使 Reset 再放回到池子中,这些 byte slice 的容量不会改变,所占的空间依然很大。而且,因为 Pool 回收的机制,这些大的 Buffer 可能不被回收,而是会一直占用很大的空间,这属于内存泄漏的问题。
即使是 Go 的标准库,在内存泄漏这个问题上也栽了几次坑,比如 issue 23199、@dsnet提供了一个简单的可重现的例子,演示了内存泄漏的问题。再比如 encoding、json 中类似的问题:将容量已经变得很大的 Buffer 再放回 Pool 中,导致内存泄漏。后来在元素放回时,增加了检查逻辑,改成放回的超过一定大小的 buffer,就直接丢弃掉,不再放到池子中,如下所示
1 | func putEncodeState(e *encodeState){ |
在使用 sync.Pool 回收 buffer 的时候,一定要检查回收的对象的大小。如果 buffer 太大,就不要回收了,否则就太浪费了。
内存浪费
除了内存泄漏以外,还有一种浪费的情况,就是池子中的 buffer 都比较大,但在实际使用的时候,很多时候只需要一个小的 buffer,这也是一种浪费现象。接下来,我就讲解一下这种情况的处理方法。
要做到物尽其用,尽可能不浪费的话,我们可以将 buffer 池分成几层。首先,小于 512 byte 的元素的 buffer 占一个池子;其次,小于 1K byte 大小的元素占一个池子;再次,小于 4K byte 大小的元素占一个池子。这样分成几个池子以后,就可以根据需要,到所需大小的池子中获取 buffer 了。
1 | var ( |
YouTube 开源的知名项目 vitess 中提供了bucketpool的实现,它提供了更加通用的多层 buffer 池。你在使用的时候,只需要指定池子的最大和最小尺寸,vitess 就会自动计算出合适的池子数。而且,当你调用 Get 方法的时候,只需要传入你要获取的 buffer 的大小,就可以了。下面这段代码就描述了这个过程,你可以看看:
第三方库
除了这种分层的为了节省空间的 buffer 设计外,还有其它的一些第三方的库也会提供 buffer 池的功能。接下来我带你熟悉几个常用的第三方的库。
1.bytebufferpool
这是 fasthttp 作者 valyala 提供的一个 buffer 池,基本功能和 sync.Pool 相同。它的底层也是使用 sync.Pool 实现的,包括会检测最大的 buffer,超过最大尺寸的 buffer,就会被丢弃。valyala 一向很擅长挖掘系统的性能,这个库也不例外。它提供了校准(calibrate,用来动态调整创建元素的权重)的机制,可以“智能”地调整 Pool 的 defaultSize 和 maxSize。一般来说,我们使用 buffer size 的场景比较固定,所用 buffer 的大小会集中在某个范围里。有了校准的特性,bytebufferpool 就能够偏重于创建这个范围大小的 buffer,从而节省空间。
2.oxtoacart/bpool
这也是比较常用的 buffer 池,它提供了以下几种类型的 buffer。
bpool.BufferPool: 提供一个固定元素数量的 buffer 池,元素类型是 bytes.Buffer,如果超过这个数量,Put 的时候就丢弃,如果池中的元素都被取光了,会新建一个返回。Put 回去的时候,不会检测 buffer 的大小。
bpool.BytesPool:提供一个固定元素数量的 byte slice 池,元素类型是 byte slice。Put 回去的时候不检测 slice 的大小。
bpool.SizedBufferPool: 提供一个固定元素数量的 buffer 池,如果超过这个数量,Put 的时候就丢弃,如果池中的元素都被取光了,会新建一个返回。Put 回去的时候,会检测 buffer 的大小,超过指定的大小的话,就会创建一个新的满足条件的 buffer 放回去。
bpool 最大的特色就是能够保持池子中元素的数量,一旦 Put 的数量多于它的阈值,就会自动丢弃,而 sync.Pool 是一个没有限制的池子,只要 Put 就会收进去。bpool 是基于 Channel 实现的,不像 sync.Pool 为了提高性能而做了很多优化,所以,在性能上比不过 sync.Pool。不过,它提供了限制 Pool 容量的功能,所以,如果你想控制 Pool 的容量的话,可以考虑这个库。
连接池
Pool 的另一个很常用的一个场景就是保持 TCP 的连接。一个 TCP 的连接创建,需要三次握手等过程,如果是 TLS 的,还会需要更多的步骤,如果加上身份认证等逻辑的话,耗时会更长。所以,为了避免每次通讯的时候都新创建连接,我们一般会建立一个连接的池子,预先把连接创建好,或者是逐步把连接放在池子中,减少连接创建的耗时,从而提高系统的性能。
事实上,我们很少会使用 sync.Pool 去池化连接对象,原因就在于,sync.Pool 会无通知地在某个时候就把连接移除垃圾回收掉了,而我们的场景是需要长久保持这个连接,所以,我们一般会使用其它方法来池化连接,比如接下来我要讲到的几种需要保持长连接的 Pool。
标准库中的 http client 池
标准库的 http.Client 是一个 http client 的库,可以用它来访问 web 服务器。为了提高性能,这个 Client 的实现也是通过池的方法来缓存一定数量的连接,以便后续重用这些连接。
http.Client 实现连接池的代码是在 Transport 类型中,它使用 idleConn 保存持久化的可重用的长连接:
TCP 连接池
最常用的一个 TCP 连接池是 fatih 开发的fatih/pool,
虽然这个项目已经被 fatih 归档(Archived),不再维护了,但是因为它相当稳定了,我们可以开箱即用。即使你有一些特殊的需求,也可以 fork 它,然后自己再做修改。它的使用套路如下:
1 | // 工厂模式,提供创建连接的工厂方法 |
虽然我一直在说 TCP,但是它管理的是更通用的 net.Conn,不局限于 TCP 连接。
它通过把 net.Conn 包装成 PoolConn,实现了拦截 net.Conn 的 Close 方法,避免了真正地关闭底层连接,而是把这个连接放回到池中
1 | type PoolConn struct { |
它的 Pool 是通过 Channel 实现的,空闲的连接放入到 Channel 中,这也是 Channel 的一个应用场景:
1 | type channelPool struct { |
数据库连接池
标准库 sql.DB 还提供了一个通用的数据库的连接池,通过 MaxOpenConns 和 MaxIdleConns 控制最大的连接数和最大的 idle 的连接数。默认的 MaxIdleConns 是 2,这个数对于数据库相关的应用来说太小了,我们一般都会调整它。
DB 的 freeConn 保存了 idle 的连接,这样,当我们获取数据库连接的时候,它就会优先尝试从 freeConn 获取已有的连接(conn)。
Worker Pool
你已经知道,goroutine 是一个很轻量级的“纤程”,在一个服务器上可以创建十几万甚至几十万的 goroutine。但是“可以”和“合适”之间还是有区别的,你会在应用中让几十万的 goroutine 一直跑吗?基本上是不会的。
一个 goroutine 初始的栈大小是 2048 个字节,并且在需要的时候可以扩展到 1GB(具体的内容你可以课下看看代码中的配置:不同的架构最大数会不同),所以,大量的 goroutine 还是很耗资源的。同时,大量的 goroutine 对于调度和垃圾回收的耗时还是会有影响的,因此,goroutine 并不是越多越好。
有的时候,我们就会创建一个 Worker Pool 来减少 goroutine 的使用。比如,我们实现一个 TCP 服务器,如果每一个连接都要由一个独立的 goroutine 去处理的话,在大量连接的情况下,就会创建大量的 goroutine,这个时候,我们就可以创建一个固定数量的 goroutine(Worker),由这一组 Worker 去处理连接,比如 fasthttp 中的Worker Pool。
Worker 的实现也是五花八门的:
有些是在后台默默执行的,不需要等待返回结果;
有些需要等待一批任务执行完;
有些 Worker Pool 的生命周期和程序一样长;
有些只是临时使用,执行完毕后,Pool 就销毁了。
大部分的 Worker Pool 都是通过 Channel 来缓存任务的,因为 Channel 能够比较方便地实现并发的保护,有的是多个 Worker 共享同一个任务 Channel,有些是每个 Worker 都有一个独立的 Channel。
综合下来,精挑细选,我给你推荐三款易用的 Worker Pool,这三个 Worker Pool 的 API 设计简单,也比较相似,易于和项目集成,而且提供的功能也是我们常用的功能。
gammazero/workerpool:gammazero/workerpool 可以无限制地提交任务,提供了更便利的 Submit 和 SubmitWait 方法提交任务,还可以提供当前的 worker 数和任务数以及关闭 Pool 的功能。
ivpusic/grpool:grpool 创建 Pool 的时候需要提供 Worker 的数量和等待执行的任务的最大数量,任务的提交是直接往 Channel 放入任务。
类似的 Worker Pool 的实现非常多,比如还有panjf2000/ants、Jeffail/tunny 、benmanns/goworker、go-playground/pool、Sherifabdlnaby/gpool等第三方库。pond也是一个非常不错的 Worker Pool,关注度目前不是很高,但是功能非常齐全。




