想要写好Go并发不得不掌握的数据结构
Mutext
018 年,Go 开发者将 fast path 和 slow path 拆成独立的方法,以便内联,提高性能。
2019 年也有一个 Mutex 的优化,虽然没有对 Mutex 做修改,但是,对于 Mutex 唤醒后持有锁的那个 waiter,调度器可以有更高的优先级去执行,这已经是很细致的性能优化了。为了避免代码过多,这里只列出当前的 Mutex 实现。
想要理解当前的 Mutex,我们需要好好泡一杯茶,仔细地品一品了。当然,现在的 Mutex 代码已经复杂得接近不可读的状态了,而且代码也非常长,删减后占了几乎三页纸。但是,作为第一个要详细介绍的同步原语,我还是希望能更清楚地剖析 Mutex 的实现,向你展示它的演化和为了一个貌似很小的 feature 不得不将代码变得非常复杂的原因。

当然,你也可以暂时略过这一段,以后慢慢品,只需要记住,Mutex 绝不容忍一个 goroutine 被落下,永远没有机会获取锁。不抛弃不放弃是它的宗旨,而且它也尽可能地让等待较长的 goroutine 更有机会获取到锁。
1 | type Mutex struct { |
什么时候不进行自旋
- 当前锁是饥饿状态
- 当前没有上锁
- 当前自旋次数带到设定限制
不同状态的取锁方式
- 饥饿状态中一定要走先入先出队列等待唤醒
- 非饥饿状态会直接抢锁
常见的 4 种错误场景
使用 Mutex 常见的错误场景有 4 类,分别是 Lock/Unlock 不是成对出现、Copy 已使用的 Mutex、重入和死锁。下面我们一一来看。
Lock/Unlock 不是成对出现
Lock/Unlock 没有成对出现,就意味着会出现死锁的情况,或者是因为 Unlock 一个未加锁的 Mutex 而导致 panic。
我们先来看看缺少 Unlock 的场景,常见的有三种情况:
代码中有太多的 if-else 分支,可能在某个分支中漏写了 Unlock;
在重构的时候把 Unlock 给删除了;
Unlock 误写成了 Lock。
在这种情况下,锁被获取之后,就不会被释放了,这也就意味着,其它的 goroutine 永远都没机会获取到锁。
我们再来看缺少 Lock 的场景,这就很简单了,一般来说就是误操作删除了 Lock。 比如先前使用 Mutex 都是正常的,结果后来其他人重构代码的时候,由于对代码不熟悉,或者由于开发者的马虎,把 Lock 调用给删除了,或者注释掉了。比如下面的代码,mu.Lock() 一行代码被删除了,直接 Unlock 一个未加锁的 Mutex 会 panic:
Copy 已使用的 Mutex
第二种误用是 Copy 已使用的 Mutex。在正式分析这个错误之前,我先交代一个小知识点,那就是 Package sync 的同步原语在使用后是不能复制的。
我们知道 Mutex 是最常用的一个同步原语,那它也是不能复制的。为什么呢?原因在于,Mutex 是一个有状态的对象,它的 state 字段记录这个锁的状态。如果你要复制一个已经加锁的 Mutex 给一个新的变量,那么新的刚初始化的变量居然被加锁了,这显然不符合你的期望,因为你期望的是一个零值的 Mutex。关键是在并发环境下,你根本不知道要复制的 Mutex 状态是什么,因为要复制的 Mutex 是由其它 goroutine 并发访问的,状态可能总是在变化。
重入
当一个线程获取锁时,如果没有其它线程拥有这个锁,那么,这个线程就成功获取到这个锁。之后,如果其它线程再请求这个锁,就会处于阻塞等待的状态。但是,如果拥有这把锁的线程再请求这把锁的话,不会阻塞,而是成功返回,所以叫可重入锁(有时候也叫做递归锁)。只要你拥有这把锁,你可以可着劲儿地调用,比如通过递归实现一些算法,调用者不会阻塞或者死锁。
了解了可重入锁的概念,那我们来看 Mutex 使用的错误场景。划重点了:Mutex 不是可重入的锁。想想也不奇怪,因为 Mutex 的实现中没有记录哪个 goroutine 拥有这把锁。
理论上,任何 goroutine 都可以随意地 Unlock 这把锁,所以没办法计算重入条件,毕竟,“臣妾做不到啊”!
死锁
接下来,我们来看第四种错误场景:死锁。
我先解释下什么是死锁。两个或两个以上的进程(或线程,goroutine)在执行过程中,因争夺共享资源而处于一种互相等待的状态,如果没有外部干涉,它们都将无法推进下去,此时,我们称系统处于死锁状态或系统产生了死锁。
我们来分析一下死锁产生的必要条件。如果你想避免死锁,只要破坏这四个条件中的一个或者几个,就可以了。
互斥: 至少一个资源是被排他性独享的,其他线程必须处于等待状态,直到资源被释放。
持有和等待:goroutine 持有一个资源,并且还在请求其它 goroutine 持有的资源,也就是咱们常说的“吃着碗里,看着锅里”的意思。
不可剥夺:资源只能由持有它的 goroutine 来释放。
环路等待:一般来说,存在一组等待进程,P={P1,P2,…,PN},P1 等待 P2 持有的资源,P2 等待 P3 持有的资源,依此类推,最后是 PN 等待 P1 持有的资源,这就形成了一个环路等待的死结。
Go 运行时,有死锁探测的功能,能够检查出是否出现了死锁的情况,如果出现了,这个时候你就需要调整策略来处理了。
你可以引入一个第三方的锁,大家都依赖这个锁进行业务处理,比如现在政府推行的一站式政务服务中心。或者是解决持有等待问题,物业不需要看到派出所的证明才给开物业证明,等等。
WaitGroup
首先,我们看看 WaitGroup 的数据结构。它包括了一个 noCopy 的辅助字段,一个 state1 记录 WaitGroup 状态的数组。
noCopy 的辅助字段,主要就是辅助 vet 工具检查是否通过 copy 赋值这个 WaitGroup 实例。我会在后面和你详细分析这个字段;
state1,一个具有复合意义的字段,包含 WaitGroup 的计数、阻塞在检查点的 waiter 数和信号量。
WaitGroup 的数据结构定义以及 state 信息的获取方法如下:
1 | type WaitGroup struct { |
因为对 64 位整数的原子操作要求整数的地址是 64 位对齐的,所以针对 64 位和 32 位环境的 state 字段的组成是不一样的。在 64 位环境下,state1 的第一个元素是 waiter 数,第二个元素是 WaitGroup 的计数值,第三个元素是信号量。在 32 位环境下,如果 state1 不是 64 位对齐的地址,那么 state1 的第一个元素是信号量,后两个元素分别是 waiter 数和计数值。然后,我们继续深入源码,看一下 Add、Done 和 Wait 这三个方法的实现。
Add 方法主要操作的是 state 的计数部分。你可以为计数值增加一个 delta 值,内部通过原子操作把这个值加到计数值上。需要注意的是,这个 delta 也可以是个负数,相当于为计数值减去一个值,Done 方法内部其实就是通过 Add(-1) 实现的。
1 | func (wg *WaitGroup) Add(delta int) { |
Wait 方法的实现逻辑是:不断检查 state 的值。如果其中的计数值变为了 0,那么说明所有的任务已完成,调用者不必再等待,直接返回。如果计数值大于 0,说明此时还有任务没完成,那么调用者就变成了等待者,需要加入 waiter 队列,并且阻塞住自己。
1 | func (wg *WaitGroup) Wait() { |
使用 WaitGroup 时的常见错误
常见问题一:计数器设置为负值
WaitGroup 的计数器的值必须大于等于 0。我们在更改这个计数值的时候,WaitGroup 会先做检查,如果计数值被设置为负数,就会导致 panic。
不可add写为负数
不可done 比add 多
常见问题二:不期望的 Add 时机
在使用 WaitGroup 的时候,你一定要遵循的原则就是,等所有的 Add 方法调用之后再调用 Wait,否则就可能导致 panic 或者不期望的结果。
我们构造这样一个场景:只有部分的 Add/Done 执行完后,Wait 就返回。我们看一个例子:启动四个 goroutine,每个 goroutine 内部调用 Add(1) 然后调用 Done(),主 goroutine 调用 Wait 等待任务完成。
1 | func main() { |
在这个例子中,我们原本设想的是,等四个 goroutine 都执行完毕后输出 Done 的信息,但是它的错误之处在于,将 WaitGroup.Add 方法的调用放在了子 gorotuine 中。等主 goorutine 调用 Wait 的时候,因为四个任务 goroutine 一开始都休眠,所以可能 WaitGroup 的 Add 方法还没有被调用,WaitGroup 的计数还是 0,所以它并没有等待四个子 goroutine 执行完毕才继续执行,而是立刻执行了下一步。
导致这个错误的原因是,没有遵循先完成所有的 Add 之后才 Wait。要解决这个问题,一个方法是,预先设置计数值:
1 | func main() { |
另一种方法是在启动子 goroutine 之前才调用 Add:
1 | func main() { |
常见问题三:前一个 Wait 还没结束就重用 WaitGroup
只要 WaitGroup 的计数值恢复到零值的状态,那么它就可以被看作是新创建的 WaitGroup,被重复使用。
但是,如果我们在 WaitGroup 的计数值还没有恢复到零值的时候就重用,就会导致程序 panic。我们看一个例子,初始设置 WaitGroup 的计数值为 1,启动一个 goroutine 先调用 Done 方法,接着就调用 Add 方法,Add 方法有可能和主 goroutine 并发执行。
1 | func main() { |
在这个例子中,第 6 行虽然让 WaitGroup 的计数恢复到 0,但是因为第 9 行有个 waiter 在等待,如果等待 Wait 的 goroutine,刚被唤醒就和 Add 调用(第 7 行)有并发执行的冲突,所以就会出现 panic。
WaitGroup 虽然可以重用,但是是有一个前提的,那就是必须等到上一轮的 Wait 完成之后,才能重用 WaitGroup 执行下一轮的 Add/Wait,如果你在 Wait 还没执行完的时候就调用下一轮 Add 方法,就有可能出现 panic。
noCopy:辅助 vet 检查
我们刚刚在学习 WaitGroup 的数据结构时,提到了里面有一个 noCopy 字段。你还记得它的作用吗?其实,它就是指示 vet 工具在做检查的时候,这个数据结构不能做值复制使用。更严谨地说,是不能在第一次使用之后复制使用 ( must not be copied after first use)。
你可能会说了,为什么要把 noCopy 字段单独拿出来讲呢?一方面,把 noCopy 字段穿插到 waitgroup 代码中讲解,容易干扰我们对 WaitGroup 整体的理解。另一方面,也是非常重要的原因,noCopy 是一个通用的计数技术,其他并发原语中也会用到,所以单独介绍有助于你以后在实践中使用这个技术。
但是,WaitGroup 同步原语不就是 Add、Done 和 Wait 方法吗?vet 能检查出来吗?其实是可以的。通过给 WaitGroup 添加一个 noCopy 字段,我们就可以为 WaitGroup 实现 Locker 接口,这样 vet 工具就可以做复制检查了。而且因为 noCopy 字段是未输出类型,所以 WaitGroup 不会暴露 Lock/Unlock 方法。
noCopy 字段的类型是 noCopy,它只是一个辅助的、用来帮助 vet 检查用的类型:
1 | type noCopy struct{} |
如果你想要自己定义的数据结构不被复制使用,或者说,不能通过 vet 工具检查出复制使用的报警,就可以通过嵌入 noCopy 这个数据类型来实现。
Cond
Go 标准库提供 Cond 原语的目的是,为等待 / 通知场景下的并发问题提供支持。Cond 通常应用于等待某个条件的一组 goroutine,等条件变为 true 的时候,其中一个 goroutine 或者所有的 goroutine 都会被唤醒执行。
顾名思义,Cond 是和某个条件相关,这个条件需要一组 goroutine 协作共同完成,在条件还没有满足的时候,所有等待这个条件的 goroutine 都会被阻塞住,只有这一组 goroutine 通过协作达到了这个条件,等待的 goroutine 才可能继续进行下去。
那这里等待的条件是什么呢?等待的条件,可以是某个变量达到了某个阈值或者某个时间点,也可以是一组变量分别都达到了某个阈值,还可以是某个对象的状态满足了特定的条件。总结来讲,等待的条件是一种可以用来计算结果是 true 还是 false 的条件。
从开发实践上,我们真正使用 Cond 的场景比较少,因为一旦遇到需要使用 Cond 的场景,我们更多地会使用 Channel 的方式(我会在第 12 和第 13 讲展开 Channel 的用法)去实现,因为那才是更地道的 Go 语言的写法,甚至 Go 的开发者有个“把 Cond 从标准库移除”的提议(issue 21165)。而有的开发者认为,Cond 是唯一难以掌握的 Go 并发原语。至于其中原因,我先卖个关子,到这一讲的后半部分我再和你解释。
Cond 的实现
1 | type Cond |
首先,Cond 关联的 Locker 实例可以通过 c.L 访问,它内部维护着一个先入先出的等待队列。
然后,我们分别看下它的三个方法 Broadcast、Signal 和 Wait 方法。
Signal 方法,允许调用者 Caller 唤醒一个等待此 Cond 的 goroutine。如果此时没有等待的 goroutine,显然无需通知 waiter;如果 Cond 等待队列中有一个或者多个等待的 goroutine,则需要从等待队列中移除第一个 goroutine 并把它唤醒。在其他编程语言中,比如 Java 语言中,Signal 方法也被叫做 notify 方法。
Broadcast 方法,允许调用者 Caller 唤醒所有等待此 Cond 的 goroutine。如果此时没有等待的 goroutine,显然无需通知 waiter;如果 Cond 等待队列中有一个或者多个等待的 goroutine,则清空所有等待的 goroutine,并全部唤醒。在其他编程语言中,比如 Java 语言中,Broadcast 方法也被叫做 notifyAll 方法。
同样地,调用 Broadcast 方法时,也不强求你一定持有 c.L 的锁。
Wait 方法,会把调用者 Caller 放入 Cond 的等待队列中并阻塞,直到被 Signal 或者 Broadcast 的方法从等待队列中移除并唤醒。
调用 Wait 方法时必须要持有 c.L 的锁。
知道了 Cond 提供的三个方法后,我们再通过一个百米赛跑开始时的例子,来学习下 Cond 的使用方法。10 个运动员进入赛场之后需要先做拉伸活动活动筋骨,向观众和粉丝招手致敬,在自己的赛道上做好准备;等所有的运动员都准备好之后,裁判员才会打响发令枪。每个运动员做好准备之后,将 ready 加一,表明自己做好准备了,同时调用 Broadcast 方法通知裁判员。
因为裁判员只有一个,所以这里可以直接替换成 Signal 方法调用。调用 Broadcast 方法的时候,我们并没有请求 c.L 锁,只是在更改等待变量的时候才使用到了锁。裁判员会等待运动员都准备好。虽然每个运动员准备好之后都唤醒了裁判员,但是裁判员被唤醒之后需要检查等待条件是否满足(运动员都准备好了)。可以看到,裁判员被唤醒之后一定要检查等待条件,如果条件不满足还是要继续等待。
1 | func main() { |
它的复杂在于:一,这段代码有时候需要加锁,有时候可以不加;二,Wait 唤醒后需要检查条件;三,条件变量的更改,其实是需要原子操作或者互斥锁保护的。所以,有的开发者会认为,Cond 是唯一难以掌握的 Go 并发原语。
Cond 的实现原理
1 | type Cond struct { |
runtime_notifyListXXX 是运行时实现的方法,实现了一个等待 / 通知的队列。如果你想深入学习这部分,可以再去看看 runtime/sema.go 代码中。
copyChecker 是一个辅助结构,可以在运行时检查 Cond 是否被复制使用。
Signal 和 Broadcast 只涉及到 notifyList 数据结构,不涉及到锁。
Wait 把调用者加入到等待队列时会释放锁,在被唤醒之后还会请求锁。
在阻塞休眠期间,调用者是不持有锁的,这样能让其他 goroutine 有机会检查或者更新等待变量。
使用 Cond 的 2 个常见错误
以前面百米赛跑的程序为例,在调用 cond.Wait 时,把前后的 Lock/Unlock 注释掉,如下面的代码中的第 20 行和第 25 行:
1 | func main() { |
出现这个问题的原因在于,cond.Wait 方法的实现是,把当前调用者加入到 notify 队列之中后会释放锁(如果不释放锁,其他 Wait 的调用者就没有机会加入到 notify 队列中了),然后一直等待;等调用者被唤醒之后,又会去争抢这把锁。如果调用 Wait 之前不加锁的话,就有可能 Unlock 一个未加锁的 Locker。所以切记,调用 cond.Wait 方法之前一定要加锁。
使用 Cond 的另一个常见错误是,只调用了一次 Wait,没有检查等待条件是否满足,结果条件没满足,程序就继续执行了。出现这个问题的原因在于,误以为 Cond 的使用,就像 WaitGroup 那样调用一下 Wait 方法等待那么简单。比如下面的代码中,把第 21 行和第 24 行注释掉:
1 | func main() { |
运行这个程序,你会发现,可能只有几个运动员准备好之后程序就运行完了,而不是我们期望的所有运动员都准备好才进行下一步。原因在于,每一个运动员准备好之后都会唤醒所有的等待者,也就是这里的裁判员,比如第一个运动员准备好后就唤醒了裁判员,结果这个裁判员傻傻地没做任何检查,以为所有的运动员都准备好了,就继续执行了。
用例
Kubernetes 项目中定义了优先级队列 PriorityQueue 这样一个数据结构,用来实现 Pod 的调用。它内部有三个 Pod 的队列,即 activeQ、podBackoffQ 和 unschedulableQ,其中 activeQ 就是用来调度的活跃队列(heap)。
Pop 方法调用的时候,如果这个队列为空,并且这个队列没有 Close 的话,会调用 Cond 的 Wait 方法等待。
你可以看到,调用 Wait 方法的时候,调用者是持有锁的,并且被唤醒的时候检查等待条件(队列是否为空)。
1 | // 从队列中取出一个元素 |
当 activeQ 增加新的元素时,会调用条件变量的 Boradcast 方法,通知被 Pop 阻塞的调用者。
1 | // 增加元素到队列中 |
这个优先级队列被关闭的时候,也会调用 Broadcast 方法,避免被 Pop 阻塞的调用者永远 hang 住。
1 | func (p *PriorityQueue) Close() { |
Once
Once 可以用来执行且仅仅执行一次动作,常常用于单例对象的初始化场景。
看一个初始化链接的例子:
1 | package main |
这种方式虽然实现起来简单,但是有性能问题。一旦连接创建好,每次请求的时候还是得竞争锁才能读取到这个连接,这是比较浪费资源的,因为连接如果创建好之后,其实就不需要锁的保护了。怎么办呢?
once这时候就派上用处了
Once 的使用场景
sync.Once 只暴露了一个方法 Do,你可以多次调用 Do 方法,但是只有第一次调用 Do 方法时 f 参数才会执行,这里的 f 是一个无参数无返回值的函数。
1 | func (o *Once) Do(f func()) |
因为当且仅当第一次调用 Do 方法的时候参数 f 才会执行,即使第二次、第三次、第 n 次调用时 f 参数的值不一样,也不会被执行,比如下面的例子,虽然 f1 和 f2 是不同的函数,但是第二个函数 f2 就不会执行。
因为这里的 f 参数是一个无参数无返回的函数,所以你可能会通过闭包的方式引用外面的参数,比如:
1 | var addr = "baidu.com" |
而且在实际的使用中,绝大多数情况下,你会使用闭包的方式去初始化外部的一个资源。你看,Once 的使用场景很明确,所以,在标准库内部实现中也常常能看到 Once 的身影。比如标准库内部cache的实现上,就使用了 Once 初始化 Cache 资源,包括 defaultDir 值的获取:
我给你重点介绍一下很值得我们学习的 math/big/sqrt.go 中实现的一个数据结构,它通过 Once 封装了一个只初始化一次的值:
1 | // 值是3.0或者0.0的一个数据结构 |
Once 常常用来初始化单例资源,或者并发访问只需初始化一次的共享资源,或者在测试的时候初始化一次测试资源。
如何实现一个 Once?
1 | type Once struct { |
使用 Once 可能出现的 2 种错误
第一种错误:死锁
你已经知道了 Do 方法会执行一次 f,但是如果 f 中再次调用这个 Once 的 Do 方法的话,就会导致死锁的情况出现。这还不是无限递归的情况,而是的的确确的 Lock 的递归调用导致的死锁
1 | func main() { |
当然,想要避免这种情况的出现,就不要在 f 参数中调用当前的这个 Once,不管是直接的还是间接的。
第二种错误:未初始化
如果 f 方法执行的时候 panic,或者 f 执行初始化资源的时候失败了,这个时候,Once 还是会认为初次执行已经成功了,即使再次调用 Do 方法,也不会再次执行 f。
比如下面的例子,由于一些防火墙的原因,googleConn 并没有被正确的初始化,后面如果想当然认为既然执行了 Do 方法 googleConn 就已经初始化的话,会抛出空指针的错误:
1 | func main() { |
既然执行过 Once.Do 方法也可能因为函数执行失败的原因未初始化资源,并且以后也没机会再次初始化资源,那么这种初始化未完成的问题该怎么解决呢?
这里我来告诉你一招独家秘笈,我们可以自己实现一个类似 Once 的并发原语,既可以返回当前调用 Do 方法是否正确完成,还可以在初始化失败后调用 Do 方法再次尝试初始化,直到初始化成功才不再初始化了。
1 | // 一个功能更加强大的Once |
我们所做的改变就是 Do 方法和参数 f 函数都会返回 error,如果 f 执行失败,会把这个错误信息返回。
对 slowDo 方法也做了调整,如果 f 调用失败,我们不会更改 done 字段的值,这样后续的 goroutine 还会继续调用 f。如果 f 执行成功,才会修改 done 的值为 1。
Map
哈希表(Hash Table)这个数据结构,我们已经非常熟悉了。它实现的就是 key-value 之间的映射关系,主要提供的方法包括 Add、Lookup、Delete 等。因为这种数据结构是一个基础的数据结构,每个 key 都会有一个唯一的索引值,通过索引可以很快地找到对应的值,所以使用哈希表进行数据的插入和读取都是很快的。Go 语言本身就内建了这样一个数据结构,也就是 map 数据类型。
map 的基本使用方法
1 | map[K]V |
其中,key 类型的 K 必须是可比较的(comparable),也就是可以通过 == 和 != 操作符进行比较;value 的值和类型无所谓,可以是任意的类型,或者为 nil。
在 Go 语言中,bool、整数、浮点数、复数、字符串、指针、Channel、接口都是可比较的,包含可比较元素的 struct 和数组,这俩也是可比较的,而 slice、map、函数值都是不可比较的。
那么,上面这些可比较的数据类型都可以作为 map 的 key 吗?显然不是。通常情况下,我们会选择内建的基本类型,比如整数、字符串做 key 的类型,因为这样最方便。
如果要使用 struct 作为 key,我们要保证 struct 对象在逻辑上是不可变的,这样才会保证 map 的逻辑没有问题。
在 Go 中,map[key]函数返回结果可以是一个值,也可以是两个值,这是容易让人迷惑的地方。原因在于,如果获取一个不存在的 key 对应的值时,会返回零值。为了区分真正的零值和 key 不存在这两种情况,可以根据第二个返回值来区分
map 是无序的,所以当遍历一个 map 对象的时候,迭代的元素的顺序是不确定的,无法保证两次遍历的顺序是一样的,也不能保证和插入的顺序一致。那怎么办呢?如果我们想要按照 key 的顺序获取 map 的值,需要先取出所有的 key 进行排序,然后按照这个排序的 key 依次获取对应的值。而如果我们想要保证元素有序,比如按照元素插入的顺序进行遍历,可以使用辅助的数据结构,比如orderedmap,来记录插入顺序。
使用 map 的 2 种常见错误
常见错误一:未初始
和 slice 或者 Mutex、RWmutex 等 struct 类型不同,map 对象必须在使用之前初始化。如果不初始化就直接赋值的话,会出现 panic 异常,比如下面的例子,m 实例还没有初始化就直接进行操作会导致 panic(第 3 行):
1 | func main() { |
解决办法就是在第 2 行初始化这个实例(m := make(map[int]int))。
从一个 nil 的 map 对象中获取值不会 panic,而是会得到零值,所以下面的代码不会报错:
1 | func main() { |
这个例子很简单,我们可以意识到 map 的初始化问题。但有时候 map 作为一个 struct 字段的时候,就很容易忘记初始化了。
所以,关于初始化这一点,我再强调一下,目前还没有工具可以检查,我们只能记住“别忘记初始化”这一条规则。
常见错误二:并发读写
对于 map 类型,另一个很容易犯的错误就是并发访问问题。这个易错点,相当令人讨厌,如果没有注意到并发问题,程序在运行的时候就有可能出现并发读写导致的 panic。
Go 内建的 map 对象不是线程(goroutine)安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致 panic。
我们一起看一个并发访问 map 实例导致 panic 的例子:
1 | func main() { |
如何实现线程安全的 map 类型?
加读写锁:扩展 map,支持并发读写比较遗憾的是,目前 Go 还没有正式发布泛型特性,我们还不能实现一个通用的支持泛型的加锁 map。
但是,将要发布的泛型方案已经可以验证测试了,离发布也不远了,也许发布之后 sync.Map 就支持泛型了。
当然了,如果没有泛型支持,我们也能解决这个问题。我们可以通过 interface{}来模拟泛型,但还是要涉及接口和具体类型的转换,比较复杂,还不如将要发布的泛型方案更直接、性能更好。这里我以一个具体的 map 类型为例,来演示利用读写锁实现线程安全的 map[int]int 类型:
1 | type RWMap struct { // 一个读写锁保护的线程安全的map |
分片加锁:更高效的并发 map
虽然使用读写锁可以提供线程安全的 map,但是在大量并发读写的情况下,锁的竞争会非常激烈。我在第 4 讲中提到过,锁是性能下降的万恶之源之一。
在并发编程中,我们的一条原则就是尽量减少锁的使用。一些单线程单进程的应用(比如 Redis 等),基本上不需要使用锁去解决并发线程访问的问题,所以可以取得很高的性能。但是对于 Go 开发的应用程序来说,并发是常用的一个特性,在这种情况下,我们能做的就是,尽量减少锁的粒度和锁的持有时间。
减少锁的粒度常用的方法就是分片(Shard),将一把锁分成几把锁,每个锁控制一个分片。Go 比较知名的分片并发 map 的实现是orcaman/concurrent-map。
它默认采用 32 个分片,GetShard 是一个关键的方法,能够根据 key 计算出分片索引。
1 | var SHARD_COUNT = 32 |
在我个人使用并发 map 的过程中,加锁和分片加锁这两种方案都比较常用,如果是追求更高的性能,显然是分片加锁更好,因为它可以降低锁的粒度,进而提高访问此 map 对象的吞吐。如果并发性能要求不是那么高的场景,简单加锁方式更简单。
Sync.Map
Go 内建的 map 类型不是线程安全的,所以 Go 1.9 中增加了一个线程安全的 map,也就是 sync.Map。但是,我们一定要记住,这个 sync.Map 并不是用来替换内建的 map 类型的,它只能被应用在一些特殊的场景里。那这些特殊的场景是啥呢?
官方的文档中指出,在以下两个场景中使用 sync.Map,会比使用 map+RWMutex 的方式,性能要好得多:
只会增长的缓存系统中,一个 key 只写入一次而被读很多次;
多个 goroutine 为不相交的键集读、写和重写键值对。
这两个场景说得都比较笼统,而且,这些场景中还包含了一些特殊的情况。所以,官方建议你针对自己的场景做性能评测,如果确实能够显著提高性能,再使用 sync.Map。这么来看,我们能用到 sync.Map 的场景确实不多。即使是 sync.Map 的作者 Bryan C. Mills,也很少使用 sync.Map,即便是在使用 sync.Map 的时候,也是需要临时查询它的 API,才能清楚记住它的功能。所以,我们可以把 sync.Map 看成一个生产环境中很少使用的同步原语。
sync.Map 的实现
- 空间换时间。通过冗余的两个数据结构(只读的 read 字段、可写的 dirty),来减少加锁对性能的影响。对只读字段(read)的操作不需要加锁。
- 优先从 read 字段读取、更新、删除,因为对 read 字段的读取不需要锁。
- 动态调整。miss 次数多了之后,将 dirty 数据提升为 read,避免总是从 dirty 中加锁读取。
- double-checking。加锁之后先还要再检查 read 字段,确定真的不存在才操作 dirty 字段。
- 延迟删除。删除一个键值只是打标记,只有在提升 dirty 字段为 read 字段的时候才清理删除的数据。
我们先看一下 map 的数据结构:
1 | type Map struct { |
如果 dirty 字段非 nil 的话,map 的 read 字段和 dirty 字段会包含相同的非 expunged 的项,所以如果通过 read 字段更改了这个项的值,从 dirty 字段中也会读取到这个项的新值,因为本来它们指向的就是同一个地址。
dirty 包含重复项目的好处就是,一旦 miss 数达到阈值需要将 dirty 提升为 read 的话,只需简单地把 dirty 设置为 read 对象即可。不好的一点就是,当创建s dirty 对象的时候,需要逐条遍历 read,把非 expunged 的项复制到 dirty 对象中。
Store 方法
我们先来看 Store 方法,它是用来设置一个键值对,或者更新一个键值对的。
1 | func (m *Map) Store(key, value interface{}) { |
可以看出,Store 既可以是新增元素,也可以是更新元素。如果运气好的话,更新的是已存在的未被删除的元素,直接更新即可,不会用到锁。
如果运气不好,需要更新(重用)删除的对象、更新还未提升的 dirty 中的对象,或者新增加元素的时候就会使用到了锁,这个时候,性能就会下降。所以从这一点来看,sync.Map 适合那些只会增长的缓存系统,可以进行更新,但是不要删除,并且不要频繁地增加新元素。
新加的元素需要放入到 dirty 中,如果 dirty 为 nil,那么需要从 read 字段中复制出来一个 dirty 对象:
1 | func (m *Map) dirtyLocked() { |
Load 方法
Load 方法用来读取一个 key 对应的值。它也是从 read 开始处理,一开始并不需要锁
1 | func (m *Map) Load(key interface{}) (value interface{}, ok bool) { |
如果幸运的话,我们从 read 中读取到了这个 key 对应的值,那么就不需要加锁了,性能会非常好。但是,如果请求的 key 不存在或者是新加的,就需要加锁从 dirty 中读取。所以,读取不存在的 key 会因为加锁而导致性能下降,读取还没有提升的新值的情况下也会因为加锁性能下降
其中,missLocked 增加 miss 的时候,如果 miss 数等于 dirty 长度,会将 dirty 提升为 read,并将 dirty 置空。
1 | func (m *Map) missLocked() { |
Delete 方法
sync.map 的第 3 个核心方法是 Delete 方法。在 Go 1.15 中欧长坤提供了一个 LoadAndDelete 的实现(go#issue 33762),所以 Delete 方法的核心改在了对 LoadAndDelete 中实现了。同样地,Delete 方法是先从 read 操作开始,原因我们已经知道了,因为不需要锁。
1 | func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) { |
如果 read 中不存在,那么就需要从 dirty 中寻找这个项目。最终,如果项目存在就删除(将它的值标记为 nil)。如果项目不为 nil 或者没有被标记为 expunged,那么还可以把它的值返回。
最后,我补充一点,sync.map 还有一些 LoadAndDelete、LoadOrStore、Range 等辅助方法,但是没有 Len 这样查询 sync.Map 的包含项目数量的方法,并且官方也不准备提供。如果你想得到 sync.Map 的项目数量的话,你可能不得不通过 Range 逐个计数。
Pool:性能提升大杀器
Go 是一个自动垃圾回收的编程语言,采用三色并发标记算法标记对象并回收。和其它没有自动垃圾回收的编程语言不同,使用 Go 语言创建对象的时候,我们没有回收 / 释放的心理负担,想用就用,想创建就创建。
但是,如果你想使用 Go 开发一个高性能的应用程序的话,就必须考虑垃圾回收给性能带来的影响,毕竟,Go 的自动垃圾回收机制还是有一个 STW(stop-the-world,程序暂停)的时间,而且,大量地创建在堆上的对象,也会影响垃圾回收标记的时间。
所以,一般我们做性能优化的时候,会采用对象池的方式,把不用的对象回收起来,避免被垃圾回收掉,这样使用的时候就不必在堆上重新创建了。
Go 标准库中提供了一个通用的 Pool 数据结构,也就是 sync.Pool,我们使用它可以创建池化的对象。
sync.Pool
sync.Pool 数据类型用来保存一组可独立访问的临时对象。请注意这里加粗的“临时”这两个字,它说明了 sync.Pool 这个数据类型的特点,也就是说,它池化的对象会在未来的某个时候被毫无预兆地移除掉。而且,如果没有别的对象引用这个被移除的对象的话,这个被移除的对象就会被垃圾回收掉。
两个知识点你需要记住:
sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象;
sync.Pool 不可在使用之后再复制使用。
sync.Pool 的使用方法
知道了 sync.Pool 这个数据类型的特点,接下来,我们来学习下它的使用方法。其实,这个数据类型不难,它只提供了三个对外的方法:New、Get 和 Put。
New
Pool struct 包含一个 New 字段,这个字段的类型是函数 func() interface{}。当调用 Pool 的 Get 方法从池中获取元素,没有更多的空闲元素可返回时,就会调用这个 New 方法来创建新的元素。如果你没有设置 New 字段,没有更多的空闲元素可返回时,Get 方法将返回 nil,表明当前没有可用的元素。
有趣的是,New 是可变的字段。这就意味着,你可以在程序运行的时候改变创建元素的方法。当然,很少有人会这么做,因为一般我们创建元素的逻辑都是一致的,要创建的也是同一类的元素,所以你在使用 Pool 的时候也没必要玩一些“花活”,在程序运行时更改 New 的值。
Get
如果调用这个方法,就会从 Pool取走一个元素,这也就意味着,这个元素会从 Pool 中移除,返回给调用者。不过,除了返回值是正常实例化的元素,Get 方法的返回值还可能会是一个 nil(Pool.New 字段没有设置,又没有空闲元素可以返回),所以你在使用的时候,可能需要判断。
Put
这个方法用于将一个元素返还给 Pool,Pool 会把这个元素保存到池中,并且可以复用。但如果 Put 一个 nil 值,Pool 就会忽略这个值。
我们看看 sync.Pool 最常用的一个场景:buffer 池(缓冲池)。
因为 byte slice 是经常被创建销毁的一类对象,使用 buffer 池可以缓存已经创建的 byte slice,比如,著名的静态网站生成工具 Hugo 中,就包含这样的实现bufpool,你可以看一下下面这段代码:
1 | var buffers = sync.Pool{ |
除了 Hugo,这段 buffer 池的代码非常常用。很可能你在阅读其它项目的代码的时候就碰到过,或者是你自己实现 buffer 池的时候也会这么去实现,但是请你注意了,这段代码是有问题的,你一定不要将上面的代码应用到实际的产品中。它可能会有内存泄漏的问题
实现原理
当前,sync.Pool 的数据结构如下图所示:
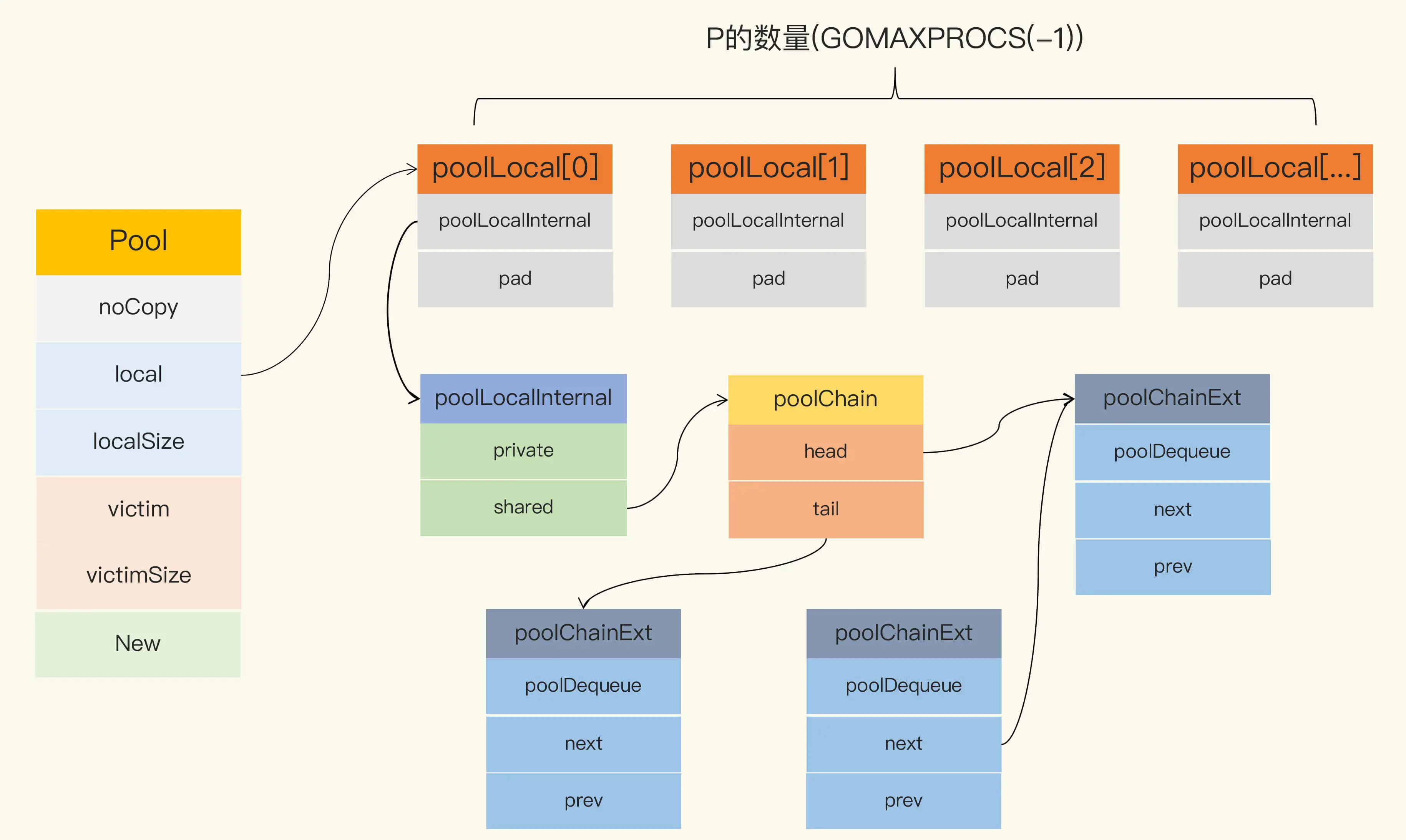
Pool 最重要的两个字段是 local 和 victim,因为它们两个主要用来存储空闲的元素。弄清楚这两个字段的处理逻辑,你就能完全掌握 sync.Pool 的实现了。下面我们来看看这两个字段的关系。
每次垃圾回收的时候,Pool 会把 victim 中的对象移除,然后把 local 的数据给 victim,这样的话,local 就会被清空,而 victim 就像一个垃圾分拣站,里面的东西可能会被当做垃圾丢弃了,但是里面有用的东西也可能被捡回来重新使用。
victim 中的元素如果被 Get 取走,那么这个元素就很幸运,因为它又“活”过来了。但是,如果这个时候 Get 的并发不是很大,元素没有被 Get 取走,那么就会被移除掉,因为没有别人引用它的话,就会被垃圾回收掉。
下面的代码是垃圾回收时 sync.Pool 的处理逻辑:
1 | func poolCleanup() { |
在这段代码中,你需要关注一下 local 字段,因为所有当前主要的空闲可用的元素都存放在 local 字段中,请求元素时也是优先从 local 字段中查找可用的元素。local 字段包含一个 poolLocalInternal 字段,并提供 CPU 缓存对齐,从而避免 false sharing。
(cpu分层读取,L1, L2, L3, 内存。当读取某一个值x做读写操作时,并不是只读取一个值,而是按块来读取(因为cpu读取,很可能会用到相邻的数据,比如把y也一起读取进去了),此时如果另一个cpu操作y,就会出现伪共享问题。解决方式:在x, y插入一些无用的内存,将y排出当前的缓存行即可。)
而 poolLocalInternal 也包含两个字段:private 和 shared。
private,代表一个缓存的元素,而且只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,所以不会有并发的问题。
shared,可以由任意的 P 访问,但是只有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相当于只有一个本地的 P 作为生产者(Producer),多个 P 作为消费者(Consumer),它是使用一个 local-free 的 queue 列表实现的。
Get
1 | func (p *Pool) Get() interface{} { |
首先,从本地的 private 字段中获取可用元素,因为没有锁,获取元素的过程会非常快,如果没有获取到,就尝试从本地的 shared 获取一个,如果还没有,会使用 getSlow 方法去其它的 shared 中“偷”一个。最后,如果没有获取到,就尝试使用 New 函数创建一个新的。
这里的重点是 getSlow 方法,我们来分析下。看名字也就知道了,它的耗时可能比较长。它首先要遍历所有的 local,尝试从它们的 shared 弹出一个元素。如果还没找到一个,那么,就开始对 victim 下手了。
在 vintim 中查询可用元素的逻辑还是一样的,先从对应的 victim 的 private 查找,如果查不到,就再从其它 victim 的 shared 中查找。
下面的代码是 getSlow 方法的主要逻辑:
1 | func (p *Pool) getSlow(pid int) interface{} { |
这里我没列出 pin 代码的实现,你只需要知道,pin 方法会将此 goroutine 固定在当前的 P 上,避免查找元素期间被其它的 P 执行。固定的好处就是查找元素期间直接得到跟这个 P 相关的 local。有一点需要注意的是,pin 方法在执行的时候,如果跟这个 P 相关的 local 还没有创建,或者运行时 P 的数量被修改了的话,就会新创建 local。
Put 方法
1 | func (p *Pool) Put(x interface{}) { |
Put 的逻辑相对简单,优先设置本地 private,如果 private 字段已经有值了,那么就把此元素 push 到本地队列中。
sync.Pool 的坑
到这里,我们就掌握了 sync.Pool 的使用方法和实现原理,接下来,我要再和你聊聊容易踩的两个坑,分别是内存泄漏和内存浪费。
内存泄漏
可以使用 sync.Pool 做 buffer 池,但是,如果用刚刚的那种方式做 buffer 池的话,可能会有内存泄漏的风险。为啥这么说呢?我们来分析一下。
取出来的 bytes.Buffer 在使用的时候,我们可以往这个元素中增加大量的 byte 数据,这会导致底层的 byte slice 的容量可能会变得很大。这个时候,即使 Reset 再放回到池子中,这些 byte slice 的容量不会改变,所占的空间依然很大。而且,因为 Pool 回收的机制,这些大的 Buffer 可能不被回收,而是会一直占用很大的空间,这属于内存泄漏的问题。
即使是 Go 的标准库,在内存泄漏这个问题上也栽了几次坑,比如 issue 23199、@dsnet提供了一个简单的可重现的例子,演示了内存泄漏的问题。再比如 encoding、json 中类似的问题:将容量已经变得很大的 Buffer 再放回 Pool 中,导致内存泄漏。后来在元素放回时,增加了检查逻辑,改成放回的超过一定大小的 buffer,就直接丢弃掉,不再放到池子中,如下所示
1 | func putEncodeState(e *encodeState){ |
在使用 sync.Pool 回收 buffer 的时候,一定要检查回收的对象的大小。如果 buffer 太大,就不要回收了,否则就太浪费了。
内存浪费
除了内存泄漏以外,还有一种浪费的情况,就是池子中的 buffer 都比较大,但在实际使用的时候,很多时候只需要一个小的 buffer,这也是一种浪费现象。接下来,我就讲解一下这种情况的处理方法。
要做到物尽其用,尽可能不浪费的话,我们可以将 buffer 池分成几层。首先,小于 512 byte 的元素的 buffer 占一个池子;其次,小于 1K byte 大小的元素占一个池子;再次,小于 4K byte 大小的元素占一个池子。这样分成几个池子以后,就可以根据需要,到所需大小的池子中获取 buffer 了。
1 | var ( |
YouTube 开源的知名项目 vitess 中提供了bucketpool的实现,它提供了更加通用的多层 buffer 池。你在使用的时候,只需要指定池子的最大和最小尺寸,vitess 就会自动计算出合适的池子数。而且,当你调用 Get 方法的时候,只需要传入你要获取的 buffer 的大小,就可以了。下面这段代码就描述了这个过程,你可以看看:
第三方库
除了这种分层的为了节省空间的 buffer 设计外,还有其它的一些第三方的库也会提供 buffer 池的功能。接下来我带你熟悉几个常用的第三方的库。
1.bytebufferpool
这是 fasthttp 作者 valyala 提供的一个 buffer 池,基本功能和 sync.Pool 相同。它的底层也是使用 sync.Pool 实现的,包括会检测最大的 buffer,超过最大尺寸的 buffer,就会被丢弃。valyala 一向很擅长挖掘系统的性能,这个库也不例外。它提供了校准(calibrate,用来动态调整创建元素的权重)的机制,可以“智能”地调整 Pool 的 defaultSize 和 maxSize。一般来说,我们使用 buffer size 的场景比较固定,所用 buffer 的大小会集中在某个范围里。有了校准的特性,bytebufferpool 就能够偏重于创建这个范围大小的 buffer,从而节省空间。
2.oxtoacart/bpool
这也是比较常用的 buffer 池,它提供了以下几种类型的 buffer。
bpool.BufferPool: 提供一个固定元素数量的 buffer 池,元素类型是 bytes.Buffer,如果超过这个数量,Put 的时候就丢弃,如果池中的元素都被取光了,会新建一个返回。Put 回去的时候,不会检测 buffer 的大小。
bpool.BytesPool:提供一个固定元素数量的 byte slice 池,元素类型是 byte slice。Put 回去的时候不检测 slice 的大小。
bpool.SizedBufferPool: 提供一个固定元素数量的 buffer 池,如果超过这个数量,Put 的时候就丢弃,如果池中的元素都被取光了,会新建一个返回。Put 回去的时候,会检测 buffer 的大小,超过指定的大小的话,就会创建一个新的满足条件的 buffer 放回去。
bpool 最大的特色就是能够保持池子中元素的数量,一旦 Put 的数量多于它的阈值,就会自动丢弃,而 sync.Pool 是一个没有限制的池子,只要 Put 就会收进去。bpool 是基于 Channel 实现的,不像 sync.Pool 为了提高性能而做了很多优化,所以,在性能上比不过 sync.Pool。不过,它提供了限制 Pool 容量的功能,所以,如果你想控制 Pool 的容量的话,可以考虑这个库。
连接池
Pool 的另一个很常用的一个场景就是保持 TCP 的连接。一个 TCP 的连接创建,需要三次握手等过程,如果是 TLS 的,还会需要更多的步骤,如果加上身份认证等逻辑的话,耗时会更长。所以,为了避免每次通讯的时候都新创建连接,我们一般会建立一个连接的池子,预先把连接创建好,或者是逐步把连接放在池子中,减少连接创建的耗时,从而提高系统的性能。
事实上,我们很少会使用 sync.Pool 去池化连接对象,原因就在于,sync.Pool 会无通知地在某个时候就把连接移除垃圾回收掉了,而我们的场景是需要长久保持这个连接,所以,我们一般会使用其它方法来池化连接,比如接下来我要讲到的几种需要保持长连接的 Pool。
标准库中的 http client 池
标准库的 http.Client 是一个 http client 的库,可以用它来访问 web 服务器。为了提高性能,这个 Client 的实现也是通过池的方法来缓存一定数量的连接,以便后续重用这些连接。
http.Client 实现连接池的代码是在 Transport 类型中,它使用 idleConn 保存持久化的可重用的长连接:
TCP 连接池
最常用的一个 TCP 连接池是 fatih 开发的fatih/pool,
虽然这个项目已经被 fatih 归档(Archived),不再维护了,但是因为它相当稳定了,我们可以开箱即用。即使你有一些特殊的需求,也可以 fork 它,然后自己再做修改。它的使用套路如下:
1 | // 工厂模式,提供创建连接的工厂方法 |
虽然我一直在说 TCP,但是它管理的是更通用的 net.Conn,不局限于 TCP 连接。
它通过把 net.Conn 包装成 PoolConn,实现了拦截 net.Conn 的 Close 方法,避免了真正地关闭底层连接,而是把这个连接放回到池中
1 | type PoolConn struct { |
它的 Pool 是通过 Channel 实现的,空闲的连接放入到 Channel 中,这也是 Channel 的一个应用场景:
1 | type channelPool struct { |
数据库连接池
标准库 sql.DB 还提供了一个通用的数据库的连接池,通过 MaxOpenConns 和 MaxIdleConns 控制最大的连接数和最大的 idle 的连接数。默认的 MaxIdleConns 是 2,这个数对于数据库相关的应用来说太小了,我们一般都会调整它。
DB 的 freeConn 保存了 idle 的连接,这样,当我们获取数据库连接的时候,它就会优先尝试从 freeConn 获取已有的连接(conn)。
Worker Pool
你已经知道,goroutine 是一个很轻量级的“纤程”,在一个服务器上可以创建十几万甚至几十万的 goroutine。但是“可以”和“合适”之间还是有区别的,你会在应用中让几十万的 goroutine 一直跑吗?基本上是不会的。
一个 goroutine 初始的栈大小是 2048 个字节,并且在需要的时候可以扩展到 1GB(具体的内容你可以课下看看代码中的配置:不同的架构最大数会不同),所以,大量的 goroutine 还是很耗资源的。同时,大量的 goroutine 对于调度和垃圾回收的耗时还是会有影响的,因此,goroutine 并不是越多越好。
有的时候,我们就会创建一个 Worker Pool 来减少 goroutine 的使用。比如,我们实现一个 TCP 服务器,如果每一个连接都要由一个独立的 goroutine 去处理的话,在大量连接的情况下,就会创建大量的 goroutine,这个时候,我们就可以创建一个固定数量的 goroutine(Worker),由这一组 Worker 去处理连接,比如 fasthttp 中的Worker Pool。
Worker 的实现也是五花八门的:
有些是在后台默默执行的,不需要等待返回结果;
有些需要等待一批任务执行完;
有些 Worker Pool 的生命周期和程序一样长;
有些只是临时使用,执行完毕后,Pool 就销毁了。
大部分的 Worker Pool 都是通过 Channel 来缓存任务的,因为 Channel 能够比较方便地实现并发的保护,有的是多个 Worker 共享同一个任务 Channel,有些是每个 Worker 都有一个独立的 Channel。
综合下来,精挑细选,我给你推荐三款易用的 Worker Pool,这三个 Worker Pool 的 API 设计简单,也比较相似,易于和项目集成,而且提供的功能也是我们常用的功能。
gammazero/workerpool:gammazero/workerpool 可以无限制地提交任务,提供了更便利的 Submit 和 SubmitWait 方法提交任务,还可以提供当前的 worker 数和任务数以及关闭 Pool 的功能。
ivpusic/grpool:grpool 创建 Pool 的时候需要提供 Worker 的数量和等待执行的任务的最大数量,任务的提交是直接往 Channel 放入任务。
类似的 Worker Pool 的实现非常多,比如还有panjf2000/ants、Jeffail/tunny 、benmanns/goworker、go-playground/pool、Sherifabdlnaby/gpool等第三方库。pond也是一个非常不错的 Worker Pool,关注度目前不是很高,但是功能非常齐全。
Context
如果我们遇到了下面的一些场景,也可以考虑使用 Context:
上下文信息传递 (request-scoped),比如处理 http 请求、在请求处理链路上传递信息;
控制子 goroutine 的运行;
超时控制的方法调用;
可以取消的方法调用。
所以,我们需要掌握 Context 的具体用法,这样才能在不影响主要业务流程实现的时候,实现一些通用的信息传递,或者是能够和其它 goroutine 协同工作,提供 timeout、cancel 等机制。
Context 基本使用方法
包 context 定义了 Context 接口,Context 的具体实现包括 4 个方法,分别是 Deadline、Done、Err 和 Value,如下所示:
1 | type Context interface { |
Deadline 方法会返回这个 Context 被取消的截止日期。如果没有设置截止日期,ok 的值是 false。后续每次调用这个对象的 Deadline 方法时,都会返回和第一次调用相同的结果。
Done 方法返回一个 Channel 对象。在 Context 被取消时,此 Channel 会被 close,如果没被取消,可能会返回 nil。后续的 Done 调用总是返回相同的结果。当 Done 被 close 的时候,你可以通过 ctx.Err 获取错误信息。Done 这个方法名其实起得并不好,因为名字太过笼统,不能明确反映 Done 被 close 的原因,因为 cancel、timeout、deadline 都可能导致 Done 被 close,不过,目前还没有一个更合适的方法名称。
关于 Done 方法,你必须要记住的知识点就是:如果 Done 没有被 close,Err 方法返回 nil;如果 Done 被 close,Err 方法会返回 Done 被 close 的原因。
Value 返回此 ctx 中和指定的 key 相关联的 value。
- context.Background():返回一个非 nil 的、空的 Context,没有任何值,不会被 cancel,不会超时,没有截止日期。一般用在主函数、初始化、测试以及创建根 Context 的时候。
- context.TODO():返回一个非 nil 的、空的 Context,没有任何值,不会被 cancel,不会超时,没有截止日期。当你不清楚是否该用 Context,或者目前还不知道要传递一些什么上下文信息的时候,就可以使用这个方法。
创建特殊用途 Context 的方法
几种创建特殊用途 Context 的方法:WithValue、WithCancel、WithTimeout 和 WithDeadline,包括它们的功能以及实现方式。
WithValue
WithValue 基于 parent Context 生成一个新的 Context,保存了一个 key-value 键值对。它常常用来传递上下文。
1 | type valueCtx struct { |
它持有一个 key-value 键值对,还持有 parent 的 Context。它覆盖了 Value 方法,优先从自己的存储中检查这个 key,不存在的话会从 parent 中继续检查。
Go 标准库实现的 Context 还实现了链式查找。如果不存在,还会向 parent Context 去查找,如果 parent 还是 valueCtx 的话,还是遵循相同的原则:valueCtx 会嵌入 parent,所以还是会查找 parent 的 Value 方法的。
WithCancel
WithCancel 方法返回 parent 的副本,只是副本中的 Done Channel 是新建的对象,它的类型是 cancelCtx。
我们常常在一些需要主动取消长时间的任务时,创建这种类型的 Context,然后把这个 Context 传给长时间执行任务的 goroutine。当需要中止任务时,我们就可以 cancel 这个 Context,这样长时间执行任务的 goroutine,就可以通过检查这个 Context,知道 Context 已经被取消了。
WithCancel 返回值中的第二个值是一个 cancel 函数。其实,这个返回值的名称(cancel)和类型(Cancel)也非常迷惑人。
记住,不是只有你想中途放弃,才去调用 cancel,只要你的任务正常完成了,就需要调用 cancel,这样,这个 Context 才能释放它的资源(通知它的 children 处理 cancel,从它的 parent 中把自己移除,甚至释放相关的 goroutine)。很多同学在使用这个方法的时候,都会忘记调用 cancel,切记切记,而且一定尽早释放。
1 | func WithCancel(parent Context) (ctx Context, cancel CancelFunc) { |
代码中调用的 propagateCancel 方法会顺着 parent 路径往上找,直到找到一个 cancelCtx,或者为 nil。如果不为空,就把自己加入到这个 cancelCtx 的 child,以便这个 cancelCtx 被取消的时候通知自己。如果为空,会新起一个 goroutine,由它来监听 parent 的 Done 是否已关闭。
当这个 cancelCtx 的 cancel 函数被调用的时候,或者 parent 的 Done 被 close 的时候,这个 cancelCtx 的 Done 才会被 close。
cancel 是向下传递的,如果一个 WithCancel 生成的 Context 被 cancel 时,如果它的子 Context(也有可能是孙,或者更低,依赖子的类型)也是 cancelCtx 类型的,就会被 cancel,但是不会向上传递。parent Context 不会因为子 Context 被 cancel 而 cancel。
cancelCtx 被取消时,它的 Err 字段就是下面这个 Canceled 错误:
1 | var Canceled = errors.New("context canceled") |
如果取消,取消的是哪些context?
看下cancelCtx的源码:
1 | // A cancelCtx can be canceled. When canceled, it also cancels any children |
children 是一个字典存放自己所有的下级是cancelCtx的儿子
那么是如何实现的呢
1 | func withCancel(parent Context) *cancelCtx { |
这是用父context来生成一个子CancelCtx
1 | // propagateCancel arranges for child to be canceled when parent is. |
1 | // parentCancelCtx returns the underlying *cancelCtx for parent. |
如果父亲ctx也是一个cancelCtx那么就将儿子的Cancel方法放入父亲的children字典集合中,那么我们看下Cancel方法
1 | // cancel closes c.done, cancels each of c's children, and, if |
可以看到在取消方法执行后会先去把自己的done chanel关闭,然后去取儿子字典集合中的cancel把自己的儿子的cancel方法进行执行。我们尝试去理解这个逻辑,首先要有一个概念,那就是context其实是一个子context指向父context的一个链表,每个父cancel context的儿子如果也是cancel context 那么父context的children中就会加入这个子context,我们尝试从最高级的父context进行取消那么可以思考到所有儿子cancel context的done 都会被关闭,我们再去思考如果从最低级的子context去取消那么取消的只会是子context自己。
WithTimeout
WithTimeout 其实是和 WithDeadline 一样,只不过一个参数是超时时间,一个参数是截止时间。超时时间加上当前时间,其实就是截止时间,因此,WithTimeout 的实现是:
1 | func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) { |
WithDeadline
WithDeadline 会返回一个 parent 的副本,并且设置了一个不晚于参数 d 的截止时间,类型为 timerCtx(或者是 cancelCtx)。
如果它的截止时间晚于 parent 的截止时间,那么就以 parent 的截止时间为准,并返回一个类型为 cancelCtx 的 Context,因为 parent 的截止时间到了,就会取消这个 cancelCtx。
如果当前时间已经超过了截止时间,就直接返回一个已经被 cancel 的 timerCtx。否则就会启动一个定时器,到截止时间取消这个 timerCtx。
1 | func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) { |
和 cancelCtx 一样,WithDeadline(WithTimeout)返回的 cancel 一定要调用,并且要尽可能早地被调用,这样才能尽早释放资源,不要单纯地依赖截止时间被动取消。正确的使用姿势是啥呢?我们来看一个例子。
1 | func slowOperationWithTimeout(ctx context.Context) (Result, error) { |
atomic
Mutex、RWMutex 等并发原语的实现时,你可以看到,最底层是通过 atomic 包中的一些原子操作来实现的
在很多场景中,使用并发原语实现起来比较复杂,而原子操作可以帮助我们更轻松地实现底层的优化。
原子操作的基础知识
Package sync/atomic 实现了同步算法底层的原子的内存操作原语,我们把它叫做原子操作原语,它提供了一些实现原子操作的方法。之所以叫原子操作,是因为一个原子在执行的时候,其它线程不会看到执行一半的操作结果。在其它线程看来,原子操作要么执行完了,要么还没有执行,就像一个最小的粒子 - 原子一样,不可分割。
CPU 提供了基础的原子操作,不过,不同架构的系统的原子操作是不一样的。对于单处理器单核系统来说,如果一个操作是由一个 CPU 指令来实现的,那么它就是原子操作,比如它的 XCHG 和 INC 等指令。如果操作是基于多条指令来实现的,那么,执行的过程中可能会被中断,并执行上下文切换,这样的话,原子性的保证就被打破了,因为这个时候,操作可能只执行了一半。
在多处理器多核系统中,原子操作的实现就比较复杂了。由于 cache 的存在,单个核上的单个指令进行原子操作的时候,你要确保其它处理器或者核不访问此原子操作的地址,或者是确保其它处理器或者核总是访问原子操作之后的最新的值。x86 架构中提供了指令前缀 LOCK,LOCK 保证了指令(比如 LOCK CMPXCHG op1、op2)不会受其它处理器或 CPU 核的影响,有些指令(比如 XCHG)本身就提供 Lock 的机制。不同的 CPU 架构提供的原子操作指令的方式也是不同的,比如对于多核的 MIPS 和 ARM,提供了 LL/SC(Load Link/Store Conditional)指令,可以帮助实现原子操作(ARMLL/SC 指令 LDREX 和 STREX)。因为不同的 CPU 架构甚至不同的版本提供的原子操作的指令是不同的,所以,要用一种编程语言实现支持不同架构的原子操作是相当有难度的。不过,还好这些都不需要你操心,因为 Go 提供了一个通用的原子操作的 API,将更底层的不同的架构下的实现封装成 atomic 包,提供了修改类型的原子操作(atomic read-modify-write,RMW)和加载存储类型的原子操作(Load 和 Store)的 API,稍后我会一一介绍。
atomic 原子操作的应用场景
使用 atomic 的一些方法,我们可以实现更底层的一些优化。如果使用 Mutex 等并发原语进行这些优化,虽然可以解决问题,但是这些并发原语的实现逻辑比较复杂,对性能还是有一定的影响的。
举个例子:假设你想在程序中使用一个标志(flag,比如一个 bool 类型的变量),来标识一个定时任务是否已经启动执行了,你会怎么做呢?
我们先来看看加锁的方法。如果使用 Mutex 和 RWMutex,在读取和设置这个标志的时候加锁,是可以做到互斥的、保证同一时刻只有一个定时任务在执行的,所以使用 Mutex 或者 RWMutex 是一种解决方案。
其实,这个场景中的问题不涉及到对资源复杂的竞争逻辑,只是会并发地读写这个标志,这类场景就适合使用 atomic 的原子操作。具体怎么做呢?你可以使用一个 uint32 类型的变量,如果这个变量的值是 0,就标识没有任务在执行,如果它的值是 1,就标识已经有任务在完成了。你看,是不是很简单呢?
再来看一个例子。假设你在开发应用程序的时候,需要从配置服务器中读取一个节点的配置信息。而且,在这个节点的配置发生变更的时候,你需要重新从配置服务器中拉取一份新的配置并更新。你的程序中可能有多个 goroutine 都依赖这份配置,涉及到对这个配置对象的并发读写,你可以使用读写锁实现对配置对象的保护。在大部分情况下,你也可以利用 atomic 实现配置对象的更新和加载。
atomic 原子操作还是实现 lock-free 数据结构的基石。
在实现 lock-free 的数据结构时,我们可以不使用互斥锁,这样就不会让线程因为等待互斥锁而阻塞休眠,而是让线程保持继续处理的状态。另外,不使用互斥锁的话,lock-free 的数据结构还可以提供并发的性能。
atomic 提供的方法
关于 atomic,还有一个地方你一定要记住,atomic 操作的对象是一个地址,你需要把可寻址的变量的地址作为参数传递给方法,而不是把变量的值传递给方法。
Add
1 | // AddInt32 atomically adds delta to *addr and returns the new value. |
Add 方法就是给第一个参数地址中的值增加一个 delta 值。
于有符号的整数来说,delta 可以是一个负数,相当于减去一个值。对于无符号的整数和 uinptr 类型来说,怎么实现减去一个值呢?毕竟,atomic 并没有提供单独的减法操作。
我来跟你说一种方法。你可以利用计算机补码的规则,把减法变成加法。以 uint32 类型为例:
1 | AddUint32(&x, ^uint32(c-1)). |
如果是对 uint64 的值进行操作,那么,就把上面的代码中的 uint32 替换成 uint64。尤其是减 1 这种特殊的操作,我们可以简化为:
1 | AddUint32(&x, ^uint32(0)) |
我们再来看看 CAS 方法。
CAS (CompareAndSwap)
以 int32 为例,我们学习一下 CAS 提供的功能。在 CAS 的方法签名中,需要提供要操作的地址、原数据值、新值,如下所示:
1 | func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) |
这个方法会比较当前 addr 地址里的值是不是 old,如果不等于 old,就返回 false;如果等于 old,就把此地址的值替换成 new 值,返回 true。这就相当于“判断相等才替换”。
1 | // CompareAndSwapInt32 executes the compare-and-swap operation for an int32 value. |
Swap
如果不需要比较旧值,只是比较粗暴地替换的话,就可以使用 Swap 方法,它替换后还可以返回旧值
1 | // SwapInt32 atomically stores new into *addr and returns the previous *addr value. |
Load
Load 方法会取出 addr 地址中的值,即使在多处理器、多核、有 CPU cache 的情况下,这个操作也能保证 Load 是一个原子操作。
1 | // LoadInt32 atomically loads *addr. |
Store
Store 方法会把一个值存入到指定的 addr 地址中,即使在多处理器、多核、有 CPU cache 的情况下,这个操作也能保证 Store 是一个原子操作。别的 goroutine 通过 Load 读取出来,不会看到存取了一半的值。
1 | // StoreInt32 atomically stores val into *addr. |
Value 类型
刚刚说的都是一些比较常见的类型,其实,atomic 还提供了一个特殊的类型:Value。它可以原子地存取对象类型,但也只能存取,不能 CAS 和 Swap,常常用在配置变更等场景中。
接下来,我以一个配置变更的例子,来演示 Value 类型的使用。这里定义了一个 Value 类型的变量 config, 用来存储配置信息。
首先,我们启动一个 goroutine,然后让它随机 sleep 一段时间,之后就变更一下配置,并通过我们前面学到的 Cond 并发原语,通知其它的 reader 去加载新的配置。
接下来,我们启动一个 goroutine 等待配置变更的信号,一旦有变更,它就会加载最新的配置。通过这个例子,你可以了解到 Value 的 Store/Load 方法的使用,因为它只有这两个方法,只要掌握了它们的使用,你就完全掌握了 Value 类型。
1 | type Config struct { |
第三方库的扩展
使用 atomic 实现 Lock-Free queue
atomic 常常用来实现 Lock-Free 的数据结构,这次我会给你展示一个 Lock-Free queue 的实现。Lock-Free queue 最出名的就是 Maged M. Michael 和 Michael L. Scott 1996 年发表的论文中的算法,算法比较简单,容易实现,伪代码的每一行都提供了注释,我就不在这里贴出伪代码了,因为我们使用 Go 实现这个数据结构的代码几乎和伪代码一样:
1 | package queue |
这个 lock-free 的实现使用了一个辅助头指针(head),头指针不包含有意义的数据,只是一个辅助的节点,这样的话,出队入队中的节点会更简单。入队的时候,通过 CAS 操作将一个元素添加到队尾,并且移动尾指针。出队的时候移除一个节点,并通过 CAS 操作移动 head 指针,同时在必要的时候移动尾指针
Channel
要想了解 Channel 这种 Go 编程语言中的特有的数据结构,我们要追溯到 CSP 模型,学习一下它的历史,以及它对 Go 创始人设计 Channel 类型的影响。CSP 是 Communicating Sequential Process 的简称,中文直译为通信顺序进程,或者叫做交换信息的循序进程,是用来描述并发系统中进行交互的一种模式。CSP 最早出现于计算机科学家 Tony Hoare 在 1978 年发表的论文中(你可能不熟悉 Tony Hoare 这个名字,但是你一定很熟悉排序算法中的 Quicksort 算法,他就是 Quicksort 算法的作者,图灵奖的获得者)。最初,论文中提出的 CSP 版本在本质上不是一种进程演算,而是一种并发编程语言,但之后又经过了一系列的改进,最终发展并精炼出 CSP 的理论。CSP 允许使用进程组件来描述系统,它们独立运行,并且只通过消息传递的方式通信。
Channel 的应用场景
Don’t communicate by sharing memory, share memory by communicating.Go Proverbs by Rob Pike这是 Rob Pike 在 2015 年的一次 Gopher 会议中提到的一句话,虽然有一点绕,但也指出了使用 Go 语言的哲学,我尝试着来翻译一下:“执行业务处理的 goroutine 不要通过共享内存的方式通信,而是要通过 Channel 通信的方式分享数据。”
“communicate by sharing memory”和“share memory by communicating”是两种不同的并发处理模式。“communicate by sharing memory”是传统的并发编程处理方式,就是指,共享的数据需要用锁进行保护,goroutine 需要获取到锁,才能并发访问数据。
“share memory by communicating”则是类似于 CSP 模型的方式,通过通信的方式,一个 goroutine 可以把数据的“所有权”交给另外一个 goroutine(虽然 Go 中没有“所有权”的概念,但是从逻辑上说,你可以把它理解为是所有权的转移)。
从 Channel 的历史和设计哲学上,我们就可以了解到,Channel 类型和基本并发原语是有竞争关系的,它应用于并发场景,涉及到 goroutine 之间的通讯,可以提供并发的保护,等等。
综合起来,我把 Channel 的应用场景分为五种类型。这里你先有个印象,这样你可以有目的地去学习 Channel 的基本原理。下节课我会借助具体的例子,来带你掌握这几种类型。
数据交流:当作并发的 buffer 或者 queue,解决生产者 - 消费者问题。多个 goroutine 可以并发当作生产者(Producer)和消费者(Consumer)。
数据传递:一个 goroutine 将数据交给另一个 goroutine,相当于把数据的拥有权 (引用) 托付出去。
信号通知:一个 goroutine 可以将信号 (closing、closed、data ready 等) 传递给另一个或者另一组 goroutine 。
任务编排:可以让一组 goroutine 按照一定的顺序并发或者串行的执行,这就是编排的功能。
锁:利用 Channel 也可以实现互斥锁的机制。
Channel 基本用法
你可以往 Channel 中发送数据,也可以从 Channel 中接收数据,所以,Channel 类型(为了说起来方便,我们下面都把 Channel 叫做 chan)分为只能接收、只能发送、既可以接收又可以发送三种类型。下面是它的语法定义:
1 | ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType . |
相应地,Channel 的正确语法如下:
1 | chan string // 可以发送接收string |
我们把既能接收又能发送的 chan 叫做双向的 chan,把只能发送和只能接收的 chan 叫做单向的 chan。其中,“<-”表示单向的 chan,如果你记不住,我告诉你一个简便的方法:这个箭头总是射向左边的,元素类型总在最右边。如果箭头指向 chan,就表示可以往 chan 中塞数据;如果箭头远离 chan,就表示 chan 会往外吐数据。
chan 中的元素是任意的类型,所以也可能是 chan 类型,我来举个例子,比如下面的 chan 类型也是合法的:
1 | chan<- chan int |
可是,怎么判定箭头符号属于哪个 chan 呢?其实,“<-”有个规则,总是尽量和左边的 chan 结合(The <- operator associates with the leftmost chan possible:),因此,上面的定义和下面的使用括号的划分是一样的:
1 | chan<- (chan int) // <- 和第一个chan结合 |
通过 make,我们可以初始化一个 chan,未初始化的 chan 的零值是 nil。你可以设置它的容量,比如下面的 chan 的容量是 9527,我们把这样的 chan 叫做 buffered chan;如果没有设置,它的容量是 0,我们把这样的 chan 叫做 unbuffered chan。
1 | make(chan int, 9527) |
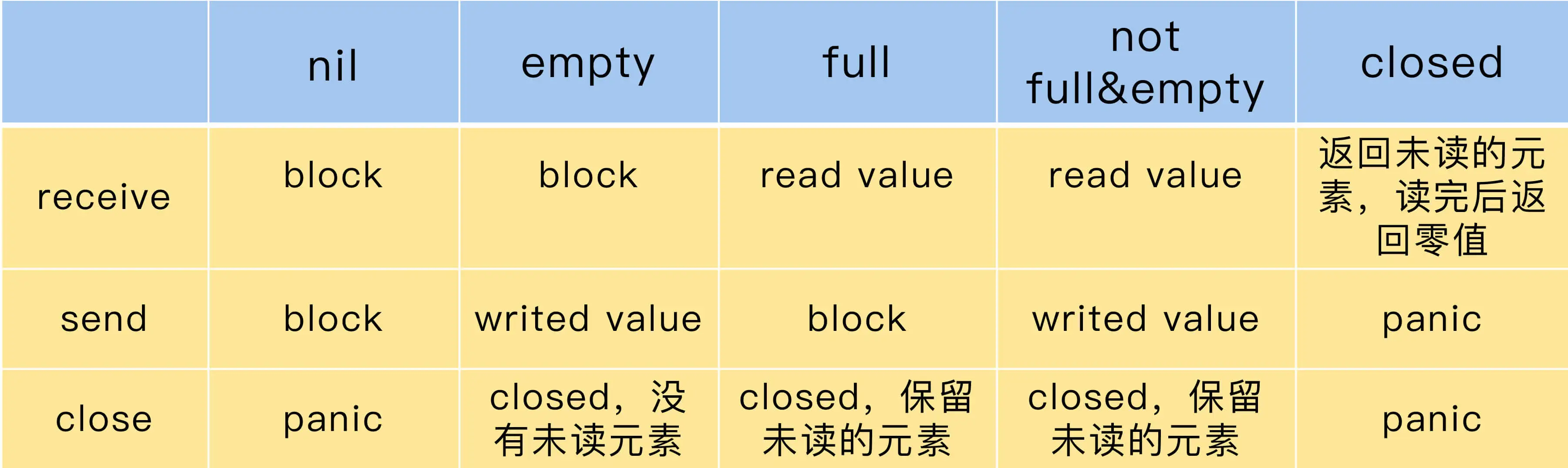
如果 chan 中还有数据,那么,从这个 chan 接收数据的时候就不会阻塞,如果 chan 还未满(“满”指达到其容量),给它发送数据也不会阻塞,否则就会阻塞。unbuffered chan 只有读写都准备好之后才不会阻塞,这也是很多使用 unbuffered chan 时的常见 Bug。
还有一个知识点需要你记住:nil 是 chan 的零值,是一种特殊的 chan,对值是 nil 的 chan 的发送接收调用者总是会阻塞。
发送数据
往 chan 中发送一个数据使用“ch<-”,发送数据是一条语句:
1 | ch <- 2000 |
这里的 ch 是 chan int 类型或者是 chan <-int。
接收数据
从 chan 中接收一条数据使用“<-ch”,接收数据也是一条语句:
1 | x := <-ch // 把接收的一条数据赋值给变量x |
这里的 ch 类型是 chan T 或者 <-chan T。
接收数据时,还可以返回两个值。第一个值是返回的 chan 中的元素,很多人不太熟悉的是第二个值。第二个值是 bool 类型,代表是否成功地从 chan 中读取到一个值,如果第二个参数是 false,chan 已经被 close 而且 chan 中没有缓存的数据,这个时候,第一个值是零值。所以,如果从 chan 读取到一个零值,可能是 sender 真正发送的零值,也可能是 closed 的并且没有缓存元素产生的零值。
其它操作
Go 内建的函数 close、cap、len 都可以操作 chan 类型:close 会把 chan 关闭掉,cap 返回 chan 的容量,len 返回 chan 中缓存的还未被取走的元素数量。
send 和 recv 都可以作为 select 语句的 case clause,如下面的例子:
1 | func main() { |
chan 还可以应用于 for-range 语句中,比如:
1 | for v := range ch { |
或者是忽略读取的值,只是清空 chan:
1 | for range ch { |
好了,到这里,Channel 的基本用法,我们就学完了。下面我从代码实现的角度分析 chan 类型的实现。毕竟,只有掌握了原理,你才能真正地用好它。
Channel 的实现原理
接下来,我会给你介绍 chan 的数据结构、初始化的方法以及三个重要的操作方法,分别是 send、recv 和 close。通过学习 Channel 的底层实现,你会对 Channel 的功能和异常情况有更深的理解。
chan 数据结构
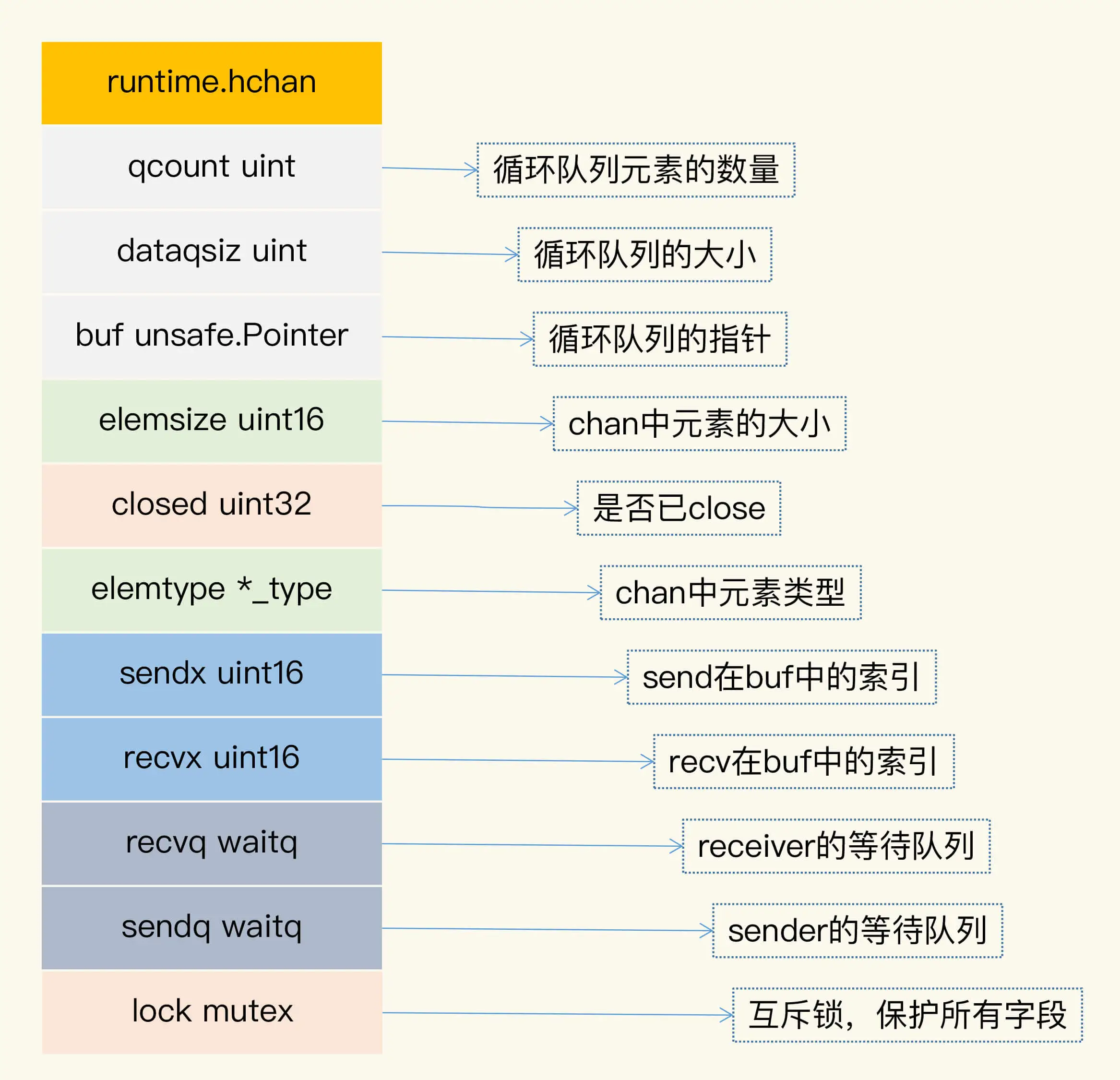
- qcount:代表 chan 中已经接收但还没被取走的元素的个数。内建函数 len 可以返回这个字段的值。
- dataqsiz:队列的大小。chan 使用一个循环队列来存放元素,循环队列很适合这种生产者 - 消费者的场景(我很好奇为什么这个字段省略 size 中的 e)
- buf:存放元素的循环队列的 buffer。
- elemtype 和 elemsize:chan 中元素的类型和 size。因为 chan 一旦声明,它的元素类型是固定的,即普通类型或者指针类型,所以元素大小也是固定的
- sendx:处理发送数据的指针在 buf 中的位置。一旦接收了新的数据,指针就会加上 elemsize,移向下一个位置。buf 的总大小是 elemsize 的整数倍,而且 buf 是一个循环列表。
- recvx:处理接收请求时的指针在 buf 中的位置。一旦取出数据,此指针会移动到下一个位置。
- recvq:chan 是多生产者多消费者的模式,如果消费者因为没有数据可读而被阻塞了,就会被加入到 recvq 队列中。
- sendq:如果生产者因为 buf 满了而阻塞,会被加入到 sendq 队列中。
初始化
看下chan 初始化makechan 的主要逻辑。主要的逻辑我都加上了注释,它会根据 chan 的容量的大小和元素的类型不同,初始化不同的存储空间:
1 | func makechan(t *chantype, size int) *hchan { |
最终,针对不同的容量和元素类型,这段代码分配了不同的对象来初始化 hchan 对象的字段,返回 hchan 对象。
send
Go 在编译发送数据给 chan 的时候,会把 send 语句转换成 chansend1 函数,chansend1 函数会调用 chansend,我们分段学习它的逻辑:
1 | func chansend1(c *hchan, elem unsafe.Pointer) { |
最开始,第一部分是进行判断:如果 chan 是 nil 的话,就把调用者 goroutine park(阻塞休眠), 调用者就永远被阻塞住了,所以,第 11 行是不可能执行到的代码。
1 | // 第二部分,如果chan没有被close,并且chan满了,直接返回 |
第二部分的逻辑是当你往一个已经满了的 chan 实例发送数据时,并且想不阻塞当前调用,那么这里的逻辑是直接返回。chansend1 方法在调用 chansend 的时候设置了阻塞参数,所以不会执行到第二部分的分支里。
1 | // 第三部分,chan已经被close的情景 |
第三部分显示的是,如果 chan 已经被 close 了,再往里面发送数据的话会 panic。
1 | // 第四部分,从接收队列中出队一个等待的receiver |
第四部分,如果等待队列中有等待的 receiver,那么这段代码就把它从队列中弹出,然后直接把数据交给它(通过 memmove(dst, src, t.size)),而不需要放入到 buf 中,速度可以更快一些。
1 | // 第五部分,buf还没满 |
第五部分说明当前没有 receiver,需要把数据放入到 buf 中,放入之后,就成功返回了。
1 | // 第六部分,buf满。 |
第六部分是处理 buf 满的情况。如果 buf 满了,发送者的 goroutine 就会加入到发送者的等待队列中,直到被唤醒。这个时候,数据或者被取走了,或者 chan 被 close 了。
recv
在处理从 chan 中接收数据时,Go 会把代码转换成 chanrecv1 函数,如果要返回两个返回值,会转换成 chanrecv2,chanrecv1 函数和 chanrecv2 会调用 chanrecv。我们分段学习它的逻辑:
1 | func chanrecv1(c *hchan, elem unsafe.Pointer) { |
chanrecv1 和 chanrecv2 传入的 block 参数的值是 true,都是阻塞方式,所以我们分析 chanrecv 的实现的时候,不考虑 block=false 的情况。
第一部分是 chan 为 nil 的情况。和 send 一样,从 nil chan 中接收(读取、获取)数据时,调用者会被永远阻塞。
1 | // 第二部分, block=false且c为空 |
第二部分你可以直接忽略,因为不是我们这次要分析的场景。
1 | // 加锁,返回时释放锁 |
第三部分是 chan 已经被 close 的情况。如果 chan 已经被 close 了,并且队列中没有缓存的元素,那么返回 true、false。
1 | // 第四部分,如果sendq队列中有等待发送的sender |
第四部分是处理 buf 满的情况。这个时候,如果是 unbuffer 的 chan,就直接将 sender 的数据复制给 receiver,否则就从队列头部读取一个值,并把这个 sender 的值加入到队列尾部。
1 | // 第五部分, 没有等待的sender, buf中有数据 |
第五部分是处理没有等待的 sender 的情况。这个是和 chansend 共用一把大锁,所以不会有并发的问题。如果 buf 有元素,就取出一个元素给 receiver。
第六部分是处理 buf 中没有元素的情况。如果没有元素,那么当前的 receiver 就会被阻塞,直到它从 sender 中接收了数据,或者是 chan 被 close,才返回
close
通过 close 函数,可以把 chan 关闭,编译器会替换成 closechan 方法的调用。下面的代码是 close chan 的主要逻辑。如果 chan 为 nil,close 会 panic;如果 chan 已经 closed,再次 close 也会 panic。否则的话,如果 chan 不为 nil,chan 也没有 closed,就把等待队列中的 sender(writer)和 receiver(reader)从队列中全部移除并唤醒。
1 | func closechan(c *hchan) { |
使用 Channel 容易犯的错误
我们来总结下会 panic 的情况,总共有 3 种:
close 为 nil 的 chan;
send 已经 close 的 chan;
close 已经 close 的 chan。
goroutine 泄漏的问题也很常见,下面的代码也是一个实际项目中的例子:
1 | func process(timeout time.Duration) bool { |
在这个例子中,process 函数会启动一个 goroutine,去处理需要长时间处理的业务,处理完之后,会发送 true 到 chan 中,目的是通知其它等待的 goroutine,可以继续处理了。
主 goroutine 接收到任务处理完成的通知,或者超时后就返回了。这段代码有问题吗?如果发生超时,process 函数就返回了,这就会导致 unbuffered 的 chan 从来就没有被读取。
我们知道,unbuffered chan 必须等 reader 和 writer 都准备好了才能交流,否则就会阻塞。超时导致未读,结果就是子 goroutine 就阻塞在第 7 行永远结束不了,进而导致 goroutine 泄漏。
解决这个 Bug 的办法很简单,就是将 unbuffered chan 改成容量为 1 的 chan,这样第 7 行就不会被阻塞了。Go 的开发者极力推荐使用 Channel,不过,这两年,大家意识到,Channel 并不是处理并发问题的“银弹”,有时候使用并发原语更简单,而且不容易出错。所以,我给你提供一套选择的方法:
共享资源的并发访问使用传统并发原语;
复杂的任务编排和消息传递使用 Channel;
消息通知机制使用 Channel,除非只想 signal 一个 goroutine,才使用 Cond;
简单等待所有任务的完成用 WaitGroup,也有 Channel 的推崇者用 Channel,都可以;
需要和 Select 语句结合,使用 Channel;
需要和超时配合时,使用 Channel 和 Context。
etcd issue 6857是一个程序 hang 住的问题:在异常情况下,没有往 chan 实例中填充所需的元素,导致等待者永远等待。具体来说,Status 方法的逻辑是生成一个 chan Status,然后把这个 chan 交给其它的 goroutine 去处理和写入数据,最后,Status 返回获取的状态信息。
1 | func (n *node)Status()Status{ |
不幸的是,如果正好节点停止了,没有 goroutine 去填充这个 chan,会导致方法 hang 在返回的那一行上。解决办法就是,在等待 status chan 返回元素的同时,也检查节点是不是已经停止了(done 这个 chan 是不是 close 了)
1 | func (n *node)Status()Status{ |
应用方法
使用反射操作 Channel
通过反射的方式执行 select 语句,在处理很多的 case clause,尤其是不定长的 case clause 的时候,非常有用。
select 语句可以处理 chan 的 send 和 recv,send 和 recv 都可以作为 case clause。可是,如果要处理 100 个 chan 呢?一万个 chan 呢?
或者是,chan 的数量在编译的时候是不定的,在运行的时候需要处理一个 slice of chan,这个时候,也没有办法在编译前写成字面意义的 select。那该怎么办?
这个时候,就要“祭”出我们的反射大法了。
通过 reflect.Select 函数,你可以将一组运行时的 case clause 传入,当作参数执行。
Go 的 select 是伪随机的,它可以在执行的 case 中随机选择一个 case,并把选择的这个 case 的索引(chosen)返回,如果没有可用的 case 返回,会返回一个 bool 类型的返回值,这个返回值用来表示是否有 case 成功被选择。如果是 recv case,还会返回接收的元素。Select 的方法签名如下:
1 | func Select(cases []SelectCase) (chosen int, recv Value, recvOK bool) |
下面,我来借助一个例子,来演示一下,动态处理两个 chan 的情形。因为这样的方式可以动态处理 case 数据,所以,你可以传入几百几千几万的 chan,这就解决了不能动态处理 n 个 chan 的问题。
首先,createCases 函数分别为每个 chan 生成了 recv case 和 send case,并返回一个 reflect.SelectCase 数组。
然后,通过一个循环 10 次的 for 循环执行 reflect.Select,这个方法会从 cases 中选择一个 case 执行。第一次肯定是 send case,因为此时 chan 还没有元素,recv 还不可用。等 chan 中有了数据以后,recv case 就可以被选择了。这样,你就可以处理不定数量的 chan 了。
1 | func main() { |
消息交流
从 chan 的内部实现看,它是以一个循环队列的方式存放数据,所以,它有时候也会被当成线程安全的队列和 buffer 使用。一个 goroutine 可以安全地往 Channel 中塞数据,另外一个 goroutine 可以安全地从 Channel 中读取数据,goroutine 就可以安全地实现信息交流了。
数据传递
“击鼓传花”的游戏很多人都玩过,花从一个人手中传给另外一个人,就有点类似流水线的操作。这个花就是数据,花在游戏者之间流转,这就类似编程中的数据传递。
有 4 个 goroutine,编号为 1、2、3、4。每秒钟会有一个 goroutine 打印出它自己的编号,要求你编写程序,让输出的编号总是按照 1、2、3、4、1、2、3、4……这个顺序打印出来。
为了实现顺序的数据传递,我们可以定义一个令牌的变量,谁得到令牌,谁就可以打印一次自己的编号,同时将令牌传递给下一个 goroutine,我们尝试使用 chan 来实现,可以看下下面的代码。
1 | type Token struct{} |
信号通知
chan 类型有这样一个特点:chan 如果为空,那么,receiver 接收数据的时候就会阻塞等待,直到 chan 被关闭或者有新的数据到来。利用这个机制,我们可以实现 wait/notify 的设计模式。
传统的并发原语 Cond 也能实现这个功能。但是,Cond 使用起来比较复杂,容易出错,而使用 chan 实现 wait/notify 模式,就方便多了。
除了正常的业务处理时的 wait/notify,我们经常碰到的一个场景,就是程序关闭的时候,我们需要在退出之前做一些清理(doCleanup 方法)的动作。这个时候,我们经常要使用 chan。
比如,使用 chan 实现程序的 graceful shutdown,在退出之前执行一些连接关闭、文件 close、缓存落盘等一些动作。
1 | func main() { |
有时候,doCleanup 可能是一个很耗时的操作,比如十几分钟才能完成,如果程序退出需要等待这么长时间,用户是不能接受的,所以,在实践中,我们需要设置一个最长的等待时间。只要超过了这个时间,程序就不再等待,可以直接退出。
所以,退出的时候分为两个阶段:
closing,代表程序退出,但是清理工作还没做;
closed,代表清理工作已经做完。
1 | func main() { |
锁
使用 chan 也可以实现互斥锁。
在 chan 的内部实现中,就有一把互斥锁保护着它的所有字段。从外在表现上,chan 的发送和接收之间也存在着 happens-before 的关系,保证元素放进去之后,receiver 才能读取到(关于 happends-before 的关系,是指事件发生的先后顺序关系,我会在下一讲详细介绍,这里你只需要知道它是一种描述事件先后顺序的方法)
要想使用 chan 实现互斥锁,至少有两种方式。
一种方式是先初始化一个 capacity 等于 1 的 Channel,然后再放入一个元素。这个元素就代表锁,谁取得了这个元素,就相当于获取了这把锁。
另一种方式是,先初始化一个 capacity 等于 1 的 Channel,它的“空槽”代表锁,谁能成功地把元素发送到这个 Channel,谁就获取了这把锁。
这是使用 Channel 实现锁的两种不同实现方式,我重点介绍下第一种。理解了这种实现方式,第二种方式也就很容易掌握了,我就不多说了。
1 | // 使用chan实现互斥锁 |
任务编排
前面所说的消息交流的场景是一个特殊的任务编排的场景,这个“击鼓传花”的模式也被称为流水线模式。在第 6 讲,我们学习了 WaitGroup,我们可以利用它实现等待模式:启动一组 goroutine 执行任务,然后等待这些任务都完成。其实,我们也可以使用 chan 实现 WaitGroup 的功能。这个比较简单,我就不举例子了,接下来我介绍几种更复杂的编排模式。这里的编排既指安排 goroutine 按照指定的顺序执行,也指多个 chan 按照指定的方式组合处理的方式。goroutine 的编排类似“击鼓传花”的例子,我们通过编排数据在 chan 之间的流转,就可以控制 goroutine 的执行。
接下来,我来重点介绍下多个 chan 的编排方式,总共 5 种,分别是 Or-Done 模式、扇入模式、扇出模式、Stream 和 map-reduce。
Or-Done 模式
首先来看 Or-Done 模式。Or-Done 模式是信号通知模式中更宽泛的一种模式。这里提到了“信号通知模式”,我先来解释一下。
我们会使用“信号通知”实现某个任务执行完成后的通知机制,在实现时,我们为这个任务定义一个类型为 chan struct{}类型的 done 变量,等任务结束后,我们就可以 close 这个变量,然后,其它 receiver 就会收到这个通知。
这是有一个任务的情况,如果有多个任务,只要有任意一个任务执行完,我们就想获得这个信号,这就是 Or-Done 模式。
比如,你发送同一个请求到多个微服务节点,只要任意一个微服务节点返回结果,就算成功,这个时候,就可以参考下面的实现:
1 | func or(channels ...<-chan interface{}) <-chan interface{} { |
在 chan 数量比较多的情况下,递归并不是一个很好的解决方式,根据这一讲最开始介绍的反射的方法,我们也可以实现 Or-Done 模式:
1 | func or(channels ...<-chan interface{}) <-chan interface{} { |
这是递归和反射两种方法实现 Or-Done 模式的代码。反射方式避免了深层递归的情况,可以处理有大量 chan 的情况。其实最笨的一种方法就是为每一个 Channel 启动一个 goroutine,不过这会启动非常多的 goroutine,太多的 goroutine 会影响性能,所以不太常用。你只要知道这种用法就行了,不用重点掌握。
扇入模式
扇入借鉴了数字电路的概念,它定义了单个逻辑门能够接受的数字信号输入最大2术语。一个逻辑门可以有多个输入,一个输出。
在软件工程中,模块的扇入是指有多少个上级模块调用它。而对于我们这里的 Channel 扇入模式来说,就是指有多个源 Channel 输入、一个目的 Channel 输出的情况。扇入比就是源 Channel 数量比 1。
每个源 Channel 的元素都会发送给目标 Channel,相当于目标 Channel 的 receiver 只需要监听目标 Channel,就可以接收所有发送给源 Channel 的数据。扇入模式也可以使用反射、递归,或者是用最笨的每个 goroutine 处理一个 Channel 的方式来实现。
这里我列举下递归和反射的方式,帮你加深一下对这个技巧的理解。反射的代码比较简短,易于理解,主要就是构造出 SelectCase slice,然后传递给 reflect.Select 语句。
1 | func fanInReflect(chans ...<-chan interface{}) <-chan interface{} { |
这里有一个 mergeTwo 的方法,是将两个 Channel 合并成一个 Channel,是扇入形式的一种特例(只处理两个 Channel)。 下面我来借助一段代码帮你理解下这个方法。
1 | func mergeTwo(a, b <-chan interface{}) <-chan interface{} { |
扇出模式
有扇入模式,就有扇出模式,扇出模式是和扇入模式相反的。
扇出模式只有一个输入源 Channel,有多个目标 Channel,扇出比就是 1 比目标 Channel 数的值,经常用在设计模式中的观察者模式中(观察者设计模式定义了对象间的一种一对多的组合关系。这样一来,一个对象的状态发生变化时,所有依赖于它的对象都会得到通知并自动刷新)。在观察者模式中,数据变动后,多个观察者都会收到这个变更信号。
下面是一个扇出模式的实现。从源 Channel 取出一个数据后,依次发送给目标 Channel。在发送给目标 Channel 的时候,可以同步发送,也可以异步发送:
1 | func fanOut(ch <-chan interface{}, out []chan interface{}, async bool) { |
Stream
这里我来介绍一种把 Channel 当作流式管道使用的方式,也就是把 Channel 看作流(Stream),提供跳过几个元素,或者是只取其中的几个元素等方法。
首先,我们提供创建流的方法。这个方法把一个数据 slice 转换成流
1 | func asStream(done <-chan struct{}, values ...interface{}) <-chan interface{} { |
流创建好以后,该咋处理呢?下面我再给你介绍下实现流的方法。
- takeN:只取流中的前 n 个数据;
- takeFn:筛选流中的数据,只保留满足条件的数据;
- takeWhile:只取前面满足条件的数据,一旦不满足条件,就不再取;
- skipN:跳过流中前几个数据;
- skipFn:跳过满足条件的数据;
- skipWhile:跳过前面满足条件的数据,一旦不满足条件,当前这个元素和以后的元素都会输出给 Channel 的 receiver。
这些方法的实现很类似,我们以 takeN 为例来具体解释一下。
1 | func takeN(done <-chan struct{}, valueStream <-chan interface{}, num int) <-chan interface{} { |
map-reduce
map-reduce 是一种处理数据的方式,最早是由 Google 公司研究提出的一种面向大规模数据处理的并行计算模型和方法,开源的版本是 hadoop,前几年比较火。
不过,我要讲的并不是分布式的 map-reduce,而是单机单进程的 map-reduce 方法。
map-reduce 分为两个步骤,第一步是映射(map),处理队列中的数据,
第二步是规约(reduce),把列表中的每一个元素按照一定的处理方式处理成结果,放入到结果队列中。就像做汉堡一样,map 就是单独处理每一种食材,reduce 就是从每一份食材中取一部分,做成一个汉堡。
我们先来看下 map 函数的处理逻辑:
1 | func mapChan(in <-chan interface{}, fn func(interface{}) interface{}) <-chan interface{} { |
reduce 函数的处理逻辑如下:
1 | func reduce(in <-chan interface{}, fn func(r, v interface{}) interface{}) interface{} { |
我们可以写一个程序,这个程序使用 map-reduce 模式处理一组整数,map 函数就是为每个整数乘以 10,reduce 函数就是把 map 处理的结果累加起来
1 | // 生成一个数据流 |
SingleFlight
SingleFlight 是 Go 开发组提供的一个扩展并发原语。它的作用是,在处理多个 goroutine 同时调用同一个函数的时候,只让一个 goroutine 去调用这个函数,等到这个 goroutine 返回结果的时候,再把结果返回给这几个同时调用的 goroutine,这样可以减少并发调用的数量。
其实,sync.Once 不是只在并发的时候保证只有一个 goroutine 执行函数 f,而是会保证永远只执行一次,而 SingleFlight 是每次调用都重新执行,并且在多个请求同时调用的时候只有一个执行。它们两个面对的场景是不同的,sync.Once 主要是用在单次初始化场景中,而 SingleFlight 主要用在合并并发请求的场景中,尤其是缓存场景
如果你学会了 SingleFlight,在面对秒杀等大并发请求的场景,而且这些请求都是读请求时,你就可以把这些请求合并为一个请求,这样,你就可以将后端服务的压力从 n 降到 1。尤其是在面对后端是数据库这样的服务的时候,采用 SingleFlight 可以极大地提高性能。那么,话不多说,就让我们开始学习 SingleFlight 吧。
实现原理
SingleFlight 使用互斥锁 Mutex 和 Map 来实现。Mutex 提供并发时的读写保护,Map 用来保存同一个 key 的正在处理(in flight)的请求。
SingleFlight 的数据结构是 Group,它提供了三个方法。Do, DoChan,Forget
- Do:这个方法执行一个函数,并返回函数执行的结果。你需要提供一个 key,对于同一个 key,在同一时间只有一个在执行,同一个 key 并发的请求会等待。第一个执行的请求返回的结果,就是它的返回结果。函数 fn 是一个无参的函数,返回一个结果或者 error,而 Do 方法会返回函数执行的结果或者是 error,shared 会指示 v 是否返回给多个请求。
- DoChan:类似 Do 方法,只不过是返回一个 chan,等 fn 函数执行完,产生了结果以后,就能从这个 chan 中接收这个结果。
- Forget:告诉 Group 忘记这个 key。这样一来,之后这个 key 请求会执行 f,而不是等待前一个未完成的 fn 函数的结果。
下面,我们来看具体的实现方法。
首先,SingleFlight 定义一个辅助对象 call,这个 call 就代表正在执行 fn 函数的请求或者是已经执行完的请求。Group 代表 SingleFlight。
1 | // 代表一个正在处理的请求,或者已经处理完的请求 |
我们只需要查看一个 Do 方法,DoChan 的处理方法是类似的。
1 | func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) { |
doCall 方法会实际调用函数 fn:
1 | func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) { |
在这段代码中,你要注意下第 7 行。在默认情况下,forgotten==false,所以第 8 行默认会被调用,也就是说,第一个请求完成后,后续的同一个 key 的请求又重新开始新一次的 fn 函数的调用。
应用场景
了解了 SingleFlight 的实现原理,下面我们来看看它都应用于什么场景中。
第一个是在net/lookup.go中,如果同时有查询同一个 host 的请求,lookupGroup 会把这些请求 merge 到一起,只需要一个请求就可以了:
1 | // lookupGroup merges LookupIPAddr calls together for lookups for the same |
第二个是 Go 在查询仓库版本信息时,将并发的请求合并成 1 个请求:
1 | func metaImportsForPrefix(importPrefix string, mod ModuleMode, security web.SecurityMode) (*urlpkg.URL, []metaImport, error) { |
需要注意的是,这里涉及到了缓存的问题。上面的代码会把结果放在缓存中,这也是常用的一种解决缓存击穿的例子。
设计缓存问题时,我们常常需要解决缓存穿透、缓存雪崩和缓存击穿问题。缓存击穿问题是指,在平常高并发的系统中,大量的请求同时查询一个 key 时,如果这个 key 正好过期失效了,就会导致大量的请求都打到数据库上。这就是缓存击穿。
用 SingleFlight 来解决缓存击穿问题再合适不过了。因为,这个时候,只要这些对同一个 key 的并发请求的其中一个到数据库中查询,就可以了,这些并发的请求可以共享同一个结果。因为是缓存查询,不用考虑幂等性问题。
事实上,在 Go 生态圈知名的缓存框架 groupcache 中,就使用了较早的 Go 标准库的 SingleFlight 实现。接下来,我就来给你介绍一下 groupcache 是如何使用 SingleFlight 解决缓存击穿问题的。groupcache 中的 SingleFlight 只有一个方法:
1 | func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) |
SingleFlight 的作用是,在加载一个缓存项的时候,合并对同一个 key 的 load 的并发请求:
1 | type Group struct { |
循环栅栏 CyclicBarrier
循环栅栏(CyclicBarrier),它常常应用于重复进行一组 goroutine 同时执行的场景中。
CyclicBarrier允许一组 goroutine 彼此等待,到达一个共同的执行点。同时,因为它可以被重复使用,所以叫循环栅栏。具体的机制是,大家都在栅栏前等待,等全部都到齐了,就抬起栅栏放行
你可能会觉得,CyclicBarrier 和 WaitGroup 的功能有点类似,确实是这样。不过,CyclicBarrier 更适合用在“固定数量的 goroutine 等待同一个执行点”的场景中,而且在放行 goroutine 之后,CyclicBarrier 可以重复利用,不像 WaitGroup 重用的时候,必须小心翼翼避免 panic。
如果使用 WaitGroup 实现的话,调用比较复杂,不像 CyclicBarrier 那么清爽。更重要的是,如果想重用 WaitGroup,你还要保证,将 WaitGroup 的计数值重置到 n 的时候不会出现并发问题。WaitGroup 更适合用在“一个 goroutine 等待一组 goroutine 到达同一个执行点”的场景中,或者是不需要重用的场景中。
实现原理
CyclicBarrier 有两个初始化方法:
第一个是 New 方法,它只需要一个参数,来指定循环栅栏参与者的数量;
第二个方法是 NewWithAction,它额外提供一个函数,可以在每一次到达执行点的时候执行一次。具体的时间点是在最后一个参与者到达之后,但是其它的参与者还未被放行之前。我们可以利用它,做放行之前的一些共享状态的更新等操作。
这两个方法的签名如下:
1 | func New(parties int) CyclicBarrier |
CyclicBarrier 是一个接口,定义的方法如下:
1 | type CyclicBarrier interface { |
循环栅栏的使用也很简单。循环栅栏的参与者只需调用 Await 等待,等所有的参与者都到达后,再执行下一步。当执行下一步的时候,循环栅栏的状态又恢复到初始的状态了,可以迎接下一轮同样多的参与者。
有一道非常经典的并发编程的题目,非常适合使用循环栅栏,下面我们来看一下。
并发趣题:一氧化二氢制造工厂
题目是这样的:有一个名叫大自然的搬运工的工厂,生产一种叫做一氧化二氢的神秘液体。这种液体的分子是由一个氧原子和两个氢原子组成的,也就是水。这个工厂有多条生产线,每条生产线负责生产氧原子或者是氢原子,每条生产线由一个 goroutine 负责。这些生产线会通过一个栅栏,只有一个氧原子生产线和两个氢原子生产线都准备好,才能生成出一个水分子,否则所有的生产线都会处于等待状态。也就是说,一个水分子必须由三个不同的生产线提供原子,而且水分子是一个一个按照顺序产生的,每生产一个水分子,就会打印出 HHO、HOH、OHH 三种形式的其中一种。HHH、OOH、OHO、HOO、OOO 都是不允许的。生产线中氢原子的生产线为 2N 条,氧原子的生产线为 N 条。
你可以先想一下,我们怎么来实现呢?首先,我们来定义一个 H2O 辅助数据类型,它包含两个信号量的字段和一个循环栅栏。
- semaH 信号量:控制氢原子。一个水分子需要两个氢原子,所以,氢原子的空槽数资源数设置为 2。
- semaO 信号量:控制氧原子。一个水分子需要一个氧原子,所以资源数的空槽数设置为 1。
- 循环栅栏:等待两个氢原子和一个氧原子填补空槽,直到任务完成。
1 | package water |
接下来,我们看看各条流水线的处理情况。流水线分为氢原子处理流水线和氧原子处理流水线,首先,我们先看一下氢原子的流水线:如果有可用的空槽,氢原子的流水线的处理方法是 hydrogen,hydrogen 方法就会占用一个空槽(h2o.semaH.Acquire),输出一个 H 字符,然后等待栅栏放行。等其它的 goroutine 填补了氢原子的另一个空槽和氧原子的空槽之后,程序才可以继续进行。
1 | func (h2o *H2O) hydrogen(releaseHydrogen func()) { |
然后是氧原子的流水线。氧原子的流水线处理方法是 oxygen, oxygen 方法是等待氧原子的空槽,然后输出一个 O,就等待栅栏放行。放行后,释放氧原子空槽位。
1 | func (h2o *H2O) oxygen(releaseOxygen func()) { |
在栅栏放行之前,只有两个氢原子的空槽位和一个氧原子的空槽位。只有等栅栏放行之后,这些空槽位才会被释放。栅栏放行,就意味着一个水分子组成成功。这个算法是不是正确呢?我们来编写一个单元测试检测一下。
1 | package water |





