go 并发中的锁
数据存储模型
go 并发中最常见的就是锁,全局锁,读写锁,以及原子操作其实都是为了解决数据竞争的问题,如果不上锁多个 go 程处理同一数据时经常会出现数据错乱,那么你搞清楚为什么会数据错乱了吗?
我一开始的理解是并发时 CPU 被竞争,赋值和读取的操作执行顺序错位导致了数据错乱,其实并不是这么简单。
用户写下的代码,先要编译成汇编代码,也就是各种指令,包括读写内存的指令。CPU 的设计者们,为了榨干 CPU 的性能,无所不用其极,各种手段都用上了,你可能听过不少,像流水线、分支预测等等。其中,为了提高读写内存的效率,会对读写指令进行重新排列,这就是所谓的 内存重排,英文为 MemoryReordering。这一部分说的是 CPU 重排,其实还有编译器重排。编译重拍这里不详解,主要说说内存重排。
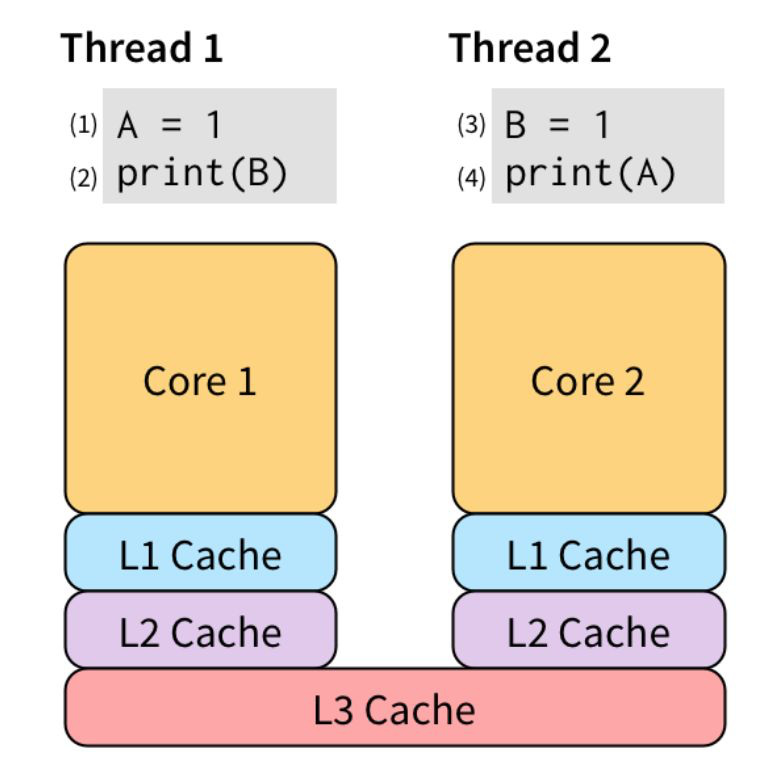
我们看一下下面三张图,Thread1 和 Thread2 是并发的两个 goroutine,交叉赋值打印,并发时CPU处理顺序是变化的,但我们假设他是按照(1)(2)(3)(4)的顺序执行的,那么你觉的打印的是什么,Thread1打印的B是0,Thread2打印的A是1。其实并不是,因为现代 CPU 为了“抚平” 内核、内存、硬盘之间的速度差异,搞出了各种策略,例如三级缓存等。为了让 (2) 不必等待 (1) 的执行“效果”可见之后才能执行,我们可以把 (1) 的效果保存到 store buffer:

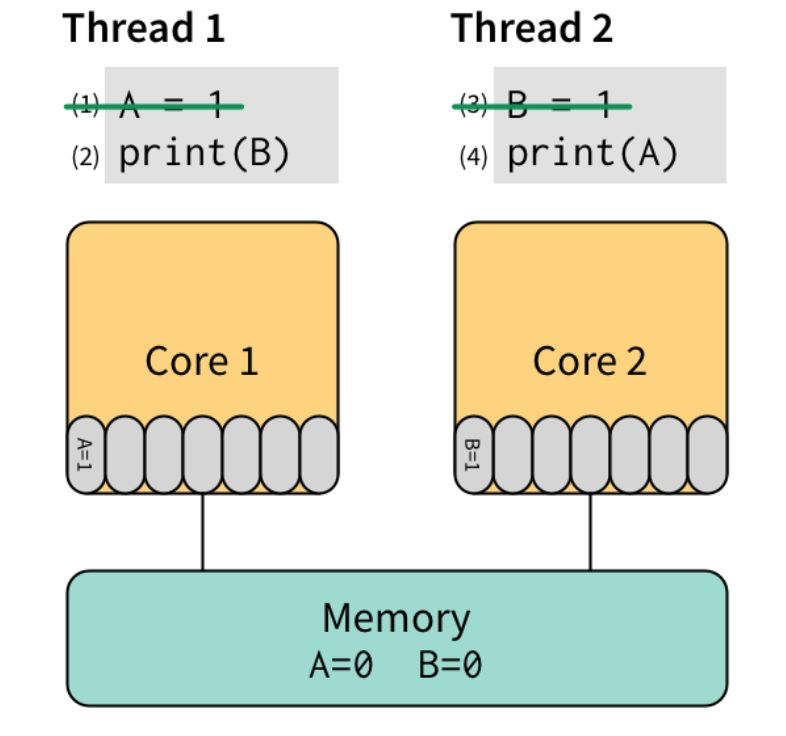
先执行 (1) 和 (3),将他们直接写入 store buffer,接着执行 (2) 和 (4)。“奇迹”要发生了:(2) 看了下 store buffer,并没有发现有 B 的值,于是从 Memory 读出了 0,(4) 同样从 Memory 读出了 0。最后,打印出了 00。
因此,对于多线程的程序,所有的 CPU 都会提供“锁”支持,称之为 barrier,或者 fence。它要求:barrier 指令要求所有对内存的操作都必须要“扩散”到 memory 之后才能继续执行其他对 memory 的操作。因此,我们可以用高级点的 atomic compare-and-swap,或者直接用更高级的锁,通常是标准库提供。
那么为什么在单一的 goroutine 中不会有问题呢,这里有一个先行发生的概念简单的说就是对于一个数据的写操作要确保先行发生于读操作,且这个写操作进行时不会有其他的写操作不确定是否会发生在它之前。这时CPU才会在写完成后读。单一的 goroutine 满足于这个条件所以不会发生数据错乱。但是并发的就有所不同。所以当多个 goroutine 访问共享变量 v 时,它们必须使用同步事件来建立先行发生这一条件来保证读操作能看到需要的写操作。建立先行发生的条件就是我们所说的锁概念,这回是不是清晰许多。
golang 中的锁 Mutex
几种锁的实现机制
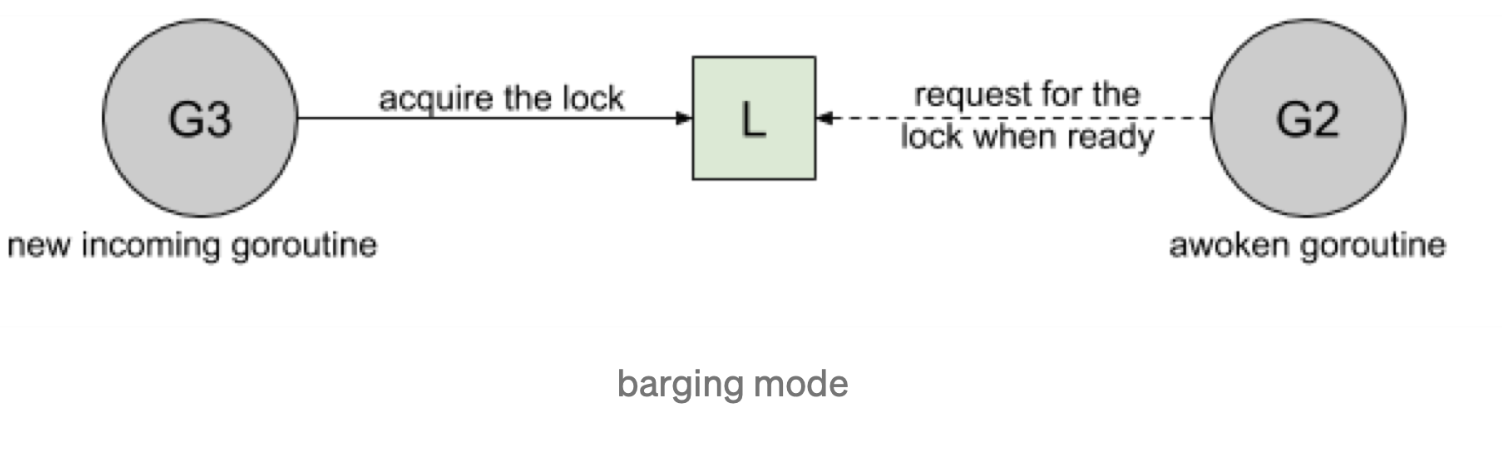
Barging. 这种模式是为了提高吞吐量,当锁被释放时,它会唤醒第一个等待者,然后把锁给第一个等待者或者给第一个请求锁的人。
Handsoff. 当锁释放时候,锁会一直持有直到第一个等待者准备好获取锁。它降低了吞吐量,因为锁被持有,即使另一个 goroutine 准备获取它。
一个互斥锁的 handsoff 会完美地平衡两个goroutine 之间的锁分配,但是会降低性能,因为它会迫使第一个 goroutine 等待锁。

Spinning. 自旋在等待队列为空或者应用程序重度使用锁时效果不错。Parking 和 Unparking goroutines 有不低的性能成本开销,相比自旋来说要慢得多。简单的说就是 goroutines 不用再去放入调度列队,会直接去获取锁。

Go 中的锁是如何实现的
Go 1.8 是 barging 和 spinning 的结合,当试图获取已经被持有的锁时,如果本地队列为空并且 P 的数量大于1,goroutine 将自旋几次(用一个 P 旋转会阻塞程序)。自旋后,goroutine park。在程序高频使用锁的情况下,它充当了一个快速路径。这是为了更大的吞吐量来设计的。但这样就会出现锁饥饿的问题。也就是公平问题。
Go 1.9 通过添加一个新的饥饿模式来解决先前解释的问题,该模式将会在释放时候触发 handsoff。所有等待锁超过一毫秒的 goroutine(也称为有界等待)将被诊断为饥饿。当被标记为饥饿状态时,unlock 方法会 handsoff 把锁直接扔给第一个等待者。
在饥饿模式下,自旋也被停用,因为传入的goroutines 将没有机会获取为下一个等待者保留的锁。
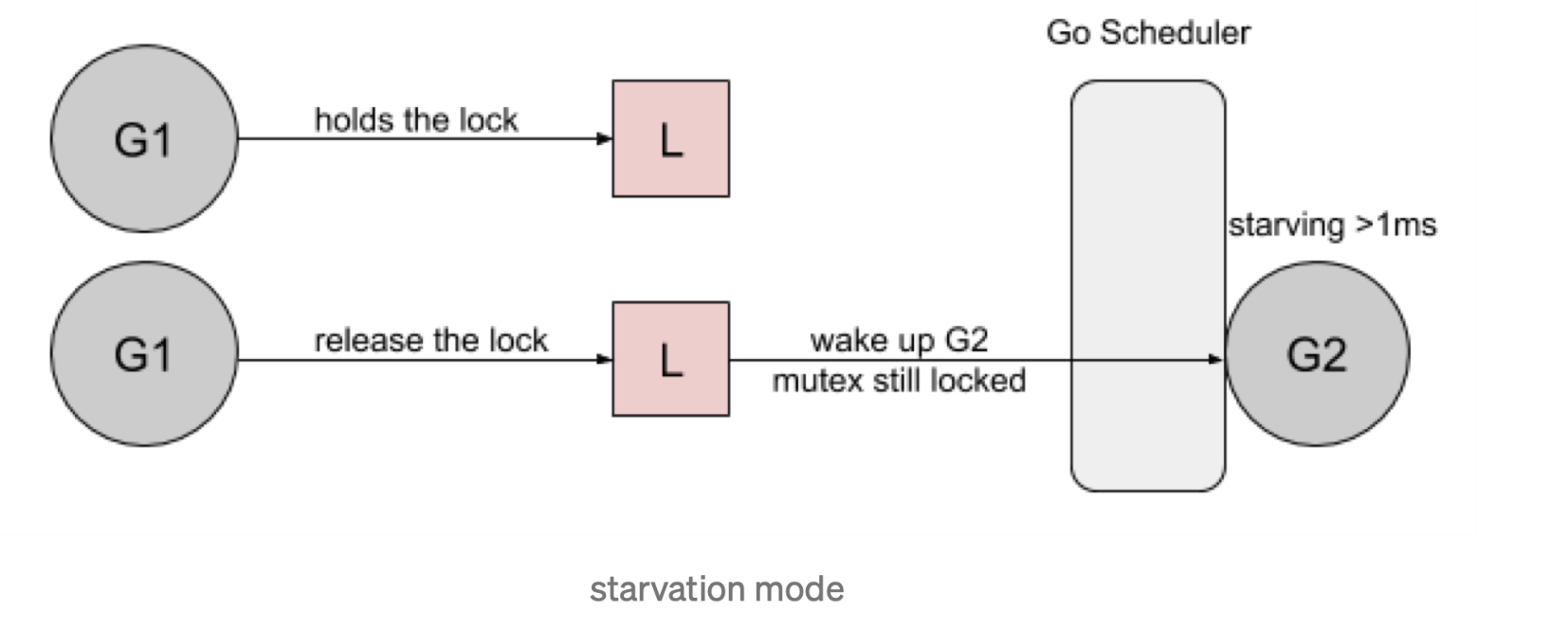
如何使用锁
go 的同步语义有 Mutex,RWMutex,Atomic,那么我们如何选择?Mutex 和 RWMutex 其实很简单看是否是读多写少,读多写少就使用RWMutex。那 Atomic 呢?
使用 benchmark 测试性能
一般我们可以用go test benchmark 来进行实践测试,看那种执行更快,举个简单的例子,某个配置文件多处需要读取,某个线程进行定期更新。对于这种读多写少的操作我们一般用读写锁或是原子读写,防止数据获取错乱。
1 |
|
此时我们使用benchmark 来看一下调用时间及次数

可以发现这个简单的例子下使用读写锁性能更好不过差异也不大,大概在两倍左右。实际使用时一定要依照测试来进行选择,不同场景下一定会有不同结果。